My project under the 2015 Julia Summer of Code program has been to develop the NullableArrays package, which provides the NullableArray data type and its respective interface. I first encountered Julia earlier this year as a suggestion for which language I ought to learn as a matriculating PhD student in statistics. This summer has been an incredible opportunity for me both to develop as a young programmer and to contribute to an open-source community as full of possibility as Julia's. I'd be remiss not to thank Alan Edelman's group at MIT, NumFocus, and the Gordon & Betty Moore Foundation for their financial support, John Myles White for his mentorship and guidance, and many others of the Julia community who have helped to contribute both to the package and to my edification as a programmer over the summer. Much of my work on this project was conducted at the Recurse Center, where I received the support of an amazing community of self-directed learners.
The NullableArray data structure
NullableArrays are array structures that efficiently represent missing values without incurring the performance difficulties that face DataArray objects, which have heretofore been used to store data that include missing values. The core issue responsible for DataArrays performance woes concerns the way in which the former represent missing values, i.e. through a token NA object of token type NAType. In particular, indexing into, say, a DataArray{Int} can return an object either of type Int or of type NAType. This design does not provide sufficient information to Julia's type inference system at JIT-compilation time to support the sort of static analysis that Julia's compiler can otherwise leverage to emit efficient machine code. We can illustrate as much through following example, in which we calculate the sum of five million random Float64s stored in a DataArray:
julia> using DataArrays
# warnings suppressed…
julia> A = rand(5_000_000);
julia> D = DataArray(A);
julia> function f(D::AbstractArray)
x = 0.0
for i in eachindex(D)
x += D[i]
end
x
end
f (generic function with 1 method)
julia> f(D);
julia> @time f(D)
0.163567 seconds (10.00 M allocations: 152.598 MB, 9.21% gc time)
2.500102419334644e6Looping through and summing the elements of D is over twenty times slower and allocates far more memory than running the same loop over A:
julia> f(A);
julia> @time f(A)
0.007465 seconds (5 allocations: 176 bytes)
2.500102419334644e6This is because the code generated for f(D) must assume that getindex(D, i) for an arbitrary index i may return an object either of type Float64 or of type NAType and hence must “box” every object returned from indexing into D. The performance penalty incurred by this requirement is reflected in the comparison above. (The interested reader can find more about these issues here.)
On the other hand, NullableArrays are designed to support the sort of static analysis used by Julia’s type inference system to generate efficient machine code. The crux of the strategy is to use a single type — Nullable{T} — to represent both missing and present values. Nullable{T} objects are specialized containers that hold precisely either one or zero values. A Nullable that wraps, say, 5 can be taken to represent a present value of 5, whereas an empty Nullable{Int} can represent a missing value that, if it had been present, would have been of type Int. Crucially, both such objects are of the same type, i.e. Nullable{Int}. Interested readers can hear a bit more on these design considerations in my JuliaCon 2015 lighting talk.
Here is the result of running the same loop over a comparable NullableArray:
julia> using NullableArrays
julia> X = NullableArray(A);
julia> function f(X::NullableArray)
x = Nullable(0.0)
for i in eachindex(X)
x += X[i]
end
x
end
f (generic function with 1 method)
julia> f(X);
julia> @time f(X)
0.009812 seconds (5 allocations: 192 bytes)
Nullable(2.500102419334644e6)As can be seen, naively looping over a NullableArray is on the same order of magnitude as naively looping over a regular Array in terms of both time elapsed and memory allocated. Below is a set of plots (drawn with Gadfly.jl) that visualize the results of running 20 benchmark samples of f over both NullableArray and DataArray arguments each consisting of 5,000,000 random Float64 values and containing either zero null entries or approximately half randomly chosen null entries.
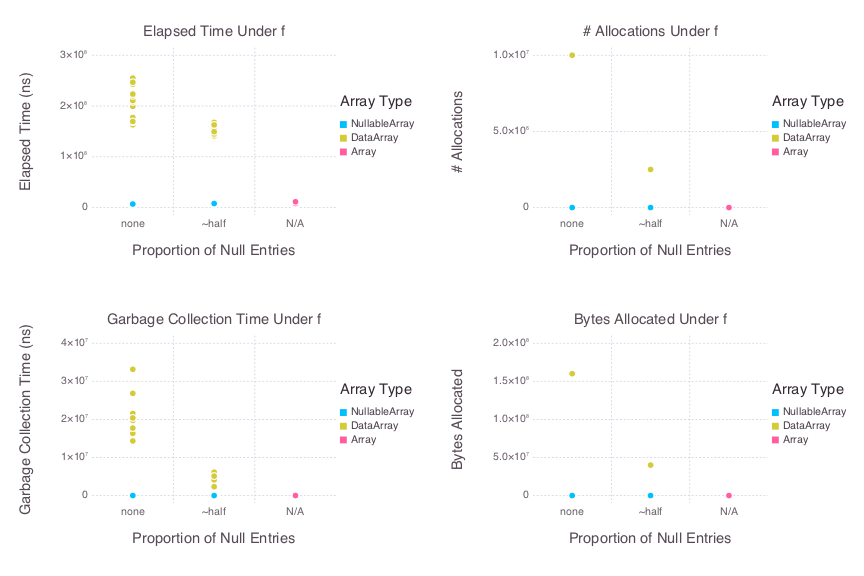
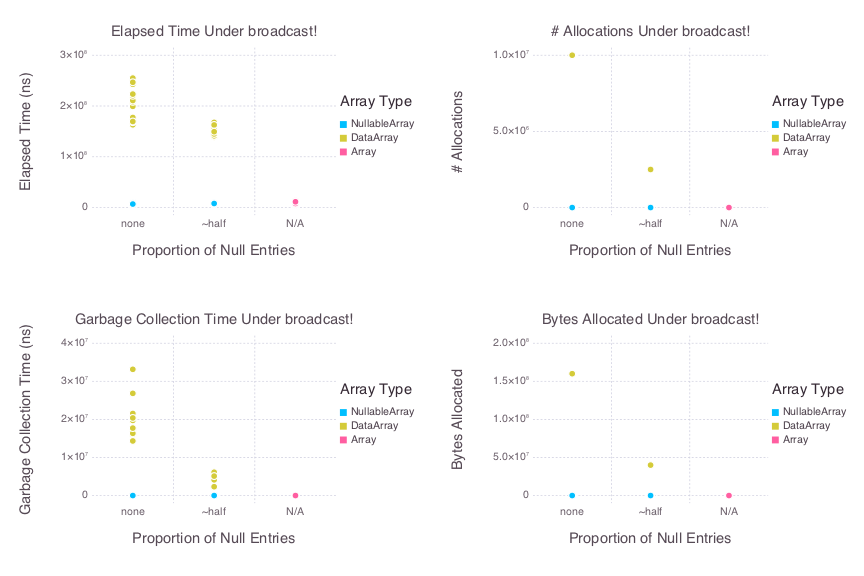
Of course, it is possible to bring the performance of such a loop over a DataArray up to par with that of a loop over an Array. But such optimizations generally introduce additional complexity that oughtn’t to be required to achieve acceptable performance in such a simple task. Considerably more complex code can be required to achieve performance in more involved implementations, such as that of broadcast!. We intend for NullableArrays to to perform well under involved tasks involving missing data while requiring as little interaction with NullableArray internals as possible. This includes allowing users to leverage extant implementations without sacrificing performance. Consider for instance the results of relying on Base’s implementation of broadcast! for DataArray and NullableArray arguments (i.e., having omitted the respective src/broadcast.jl from each package’s source code). Below are plots that visualize the results of running 20 benchmark samples of broadcast!(dest, src1, src2), where dest and src2 are 5_000_000 x 2 Arrays, NullableArrays or DataArrays, and src1 is a 5_000_000 x 1 Array, NullableArray or DataArray. As above, the NullableArray and DataArray arguments are tested in cases with either zero or approximately half null entries:
We have designed the NullableArray type to feel as much like a regular Array as possible. However, that NullableArrays return Nullable objects is a significant departure from both Array and DataArray behavior. Arguably the most important issue is to support user-defined functions that lack methods for Nullable arguments as they interact with Nullable and NullableArray objects. Throughout my project I have also worked to develop interfaces that make dealing with Nullable objects user-friendly and safe.
Given a method f defined on an argument signature of types (U1, U2, …, UN), we would like to provide an accessible, safe and performant way for a user to call f on an argument of signature (Nullable{U1}, Nullable{U2}, …, Nullable{UN}) without having to extend f herself. Doing so should return Nullable(f(get(u1), get(u1), …, get(un))) if each argument is non-null, and should return an empty Nullable if any argument is null. Systematically extending an arbitrary method f over Nullable argument signatures is often referred to as “lifting” f over the Nullable arguments.
NullableArrays offers keyword arguments for certain methods such as broadcast and map that direct the latter methods to lift passed function arguments over NullableArray arguments:
julia> X = NullableArray(collect(1:10), rand(Bool, 10))
10-element NullableArray{Int64,1}:
#NULL
#NULL
#NULL
4
5
6
7
8
#NULL
10
julia> f(x::Int) = 2x
f (generic function with 2 methods)
julia> map(f, X)
ERROR: MethodError: `f` has no method matching f(::Nullable{Int64})
Closest candidates are:
f(::Any, ::Any)
[inlined code] from /Users/David/.julia/v0.4/NullableArrays/src/map.jl:93
in _F_ at /Users/David/.julia/v0.4/NullableArrays/src/map.jl:124
in map at /Users/David/.julia/v0.4/NullableArrays/src/map.jl:172
julia> map(f, X; lift=true)
10-element NullableArray{Int64,1}:
#NULL
#NULL
#NULL
8
10
12
14
16
#NULL
20I also plan to release shortly a small package that will offer a more flexible “lift” macro, which will be able to lift function calls over Nullable arguments within a variety of expression types.
We hope that the new NullableArrays package will help to support not only Julia’s statistical computing ecosystem as it moves forward but also any endeavor that requires an efficient, developed interface for handling arrays of Nullable objects. Please do try the package, submit feature requests, report bugs, and, if you’re interested, submit a PR or two. Happy coding!