Hello, world!
In this post I'm going to briefly summarize about the machine learning models I have worked on during this summer for GSoC. I worked towards enriching model zoo of Flux.jl, a machine learning library written in Julia. My project covered Reinforcement Learning and computer vision models.
The project is spread over these 4 codebases
In the process, I could achieve most of my targets. I had to skip a few of them, and also made some unplanned models. Below, I discuss about these issues repository wise.
Flux Baselines
Flux Baselines
Flux-baselines is a collection of various Deep Reinforcement Learning models. This includes Deep Q Networks, Actor-Critic and DDPG.
Basic structure of an RL problem is as folows: There is an environment, let's say game of pong is our environment. The environment may contain many objects which interact with each other. In pong there are 3 objects: a ball and 2 paddles. The environment has a state. It is the current situation present in the environment in terms of various features of the objects in it. These features could be position, velocity, color etc. pertaining to the objects in the it. An actions needs to be chosed to play a move in the environment and obtain the next state. Actions will be chosen till the game ends. An RL model basically finds the actions that needs to be chosen.
Over past few years, deep q learning has gained lot of popularity. After the paper by Deep Mind about the Human level control sing reinforcement learning, there was no looking back. It combined the advanced in RL as well as deep learning to get an AI player which had superhuman performance. I made the basic DQN and Double DQN during the pre-GSoC phase, followed by Duel DQN in the first week on GSoC.
The idea used in the A2C model is different from the one in DQN. A2C falls in the class of "Actor-Critic" models. In AC models we have 2 neural networks, policy network and value network. policy network accepts the state of the game and returns a probability distribution over the action space. Value Nework takes the state and action chosen using policy network as input and determines how suitable is that action for that state.
DDPG is particularly useful when the actions which needs to be chosed are spread over a continuous space. one possible solution you may have in mind is that what if we discretize the action space? If we discretize it narrowly we end up with a large number of actions. If we discretize it sparsely then we lose important data.
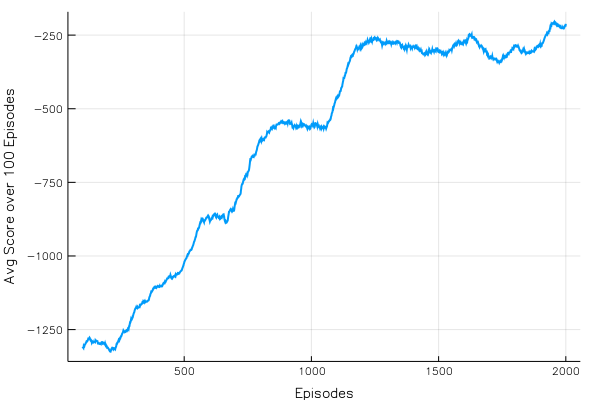
DDPG: Score vs Episodes
Some of these models have been deployed on Flux's website. CartPole example has been trained on Deep Q Networks. An Atari-Pong example will also be added in a few days. It is trained on Duel-DQN. Here is a demo of Pong trained using Flux.
Targets achieved
Extra mile
Future Work
Add more variety of models, especially the ones which have come up in the last 18 months.
Create an interface to easily train and test any environment from OpenAIGym.jl.
AlphaGo.jl
AlphaGo.jl
This mini-project of the GSoC phase 2 was the most challenging part. AlphaGo Zero is a breakthrough AI by Google DeepMind. It is an AI to play Go, which is considered to be one of most challeenging games in the world, mainly due to number of states it can lead to. AlphaGo Zero defeated the best Go player in the world. AlphaFo.jl's objective is achieve the results produced by AlphaGo Zero algorithm over Go, and achieve similar results on any zero-sum game.
Now, we have a package to train AlphaGo zero model in Julia! And it is really simple to train the model. We just have to pass the training parameters, the environment on which we want to train the model and then play with it. For more info in the AlphaGo.jl refer to the blog post.
Targets achieved
Game of Go
Monte Carlo tree search
Targets couldn't achieve
Couldn't train the model well
Extra mile
Game of Gomoku to test the algorithm (since it is easier game)
Future Work
Train a model on any game
AlphaChess
Generative Adversarial Networks
Generative Adversarial Networks
Generative Adversarial Networks
GANs have been extremely suceessful in learning the underlying representation of any data. By doing so, it can reproduce some fake data. For example the GANs trained on MNIST Human handwritten digits dataset can produce some fake images which look very similar to those in the MNIST. These neural nets have great application in image editing. It can remove certain features from the image, add some new ones; depending on the dataset. The GANs contain of two networks: generator and discriminator. Generator's objective os to generate fake images awhereas the discriminator's objective is to differentiate between the fake images generated by the generator and the real images in the dataset.




LSGAN DCGAN WGAN MADE
Targets achieved
Extra mile
Future Work
More models of GAN like infoGAN, BEGAN, CycleGAN
Some cool animations with GANs
Data pipeline for training and producing images with dataset, and GAN type as input.
Decoupled Neural Interface
Decoupled Neural Interface
Decoupled Neural Interface is a new technique to train the model. It does not use the backpropagation from the output layer right upto the input layer. Instead it uses a trick to "estimate" the gradient. It has a small linear layer neural network to predict the gradients, instead of running the backpropagation rather than finding the true gradients. The advantage of such a model is that it can be parallelized. This technique results in slight dip in the accuracy, but we have improved speed if we have parallelized the layers in the network.
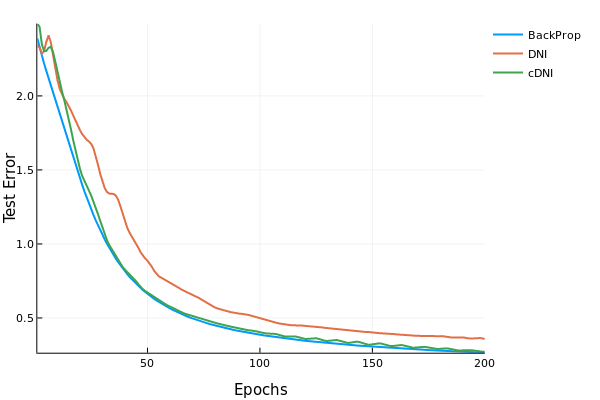
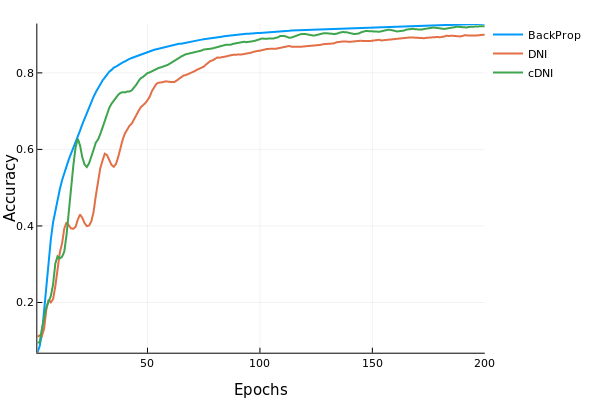
Targets achieved
Conclusion
During the past three months, I learn a lot about Reinforcement Learning and AlphaGo in particular. I experienced training an RL model for days, finally saw it working well! I encountered the issues faced in training the models and learnt to overcome them. All in all, as an aspiring ML engineer these three months have been the most productive months. I am glad that I could meet most of my objectives. I have worked on some extra models to make up for the objectives I could not meet.
Acknowledgements
I really would like to thank my mentor Mike Innes for guiding me throughout the project, and James Bradbury for his valuable inputs for improving the code in the Reinforcement Learning models. I also would like to thank Neethu Mariya Joy for deploying the trained models on the web. And last but not the least, The Julia Project and NumFOCUS: for sponsoring me and all other JSoC students for JuliaCon'18 London.