Translations: Traditional Chinese
In this blog post we will show you how to easily, efficiently, and robustly use differential equation (DiffEq) solvers with neural networks in Julia.
The Neural Ordinary Differential Equations paper has attracted significant attention even before it was awarded one of the Best Papers of NeurIPS 2018. The paper already gives many exciting results combining these two disparate fields, but this is only the beginning: neural networks and differential equations were born to be together. This blog post, a collaboration between authors of Flux, DifferentialEquations.jl and the Neural ODEs paper, will explain why, outline current and future directions for this work, and start to give a sense of what's possible with state-of-the-art tools.
The advantages of the Julia DifferentialEquations.jl library for numerically solving differential equations have been discussed in detail in other posts. Along with its extensive benchmarking against classic Fortran methods, it includes other modern features such as GPU acceleration, distributed (multi-node) parallelism, and sophisticated event handling. Recently, these native Julia differential equation solvers have successfully been embedded into the Flux deep learning package, to allow the use of a full suite of highly tested and optimized DiffEq methods within neural networks. Using the new package DiffEqFlux.jl, we will show the reader how to easily add differential equation layers to neural networks using a range of differential equations models, including stiff ordinary differential equations, stochastic differential equations, delay differential equations, and hybrid (discontinuous) differential equations.
This is the first toolbox to combine a fully-featured differential equations solver library and neural networks seamlessly together. The blog post will also show why the flexibility of a full differential equation solver suite is necessary. With the ability to fuse neural networks with ODEs, SDEs, DAEs, DDEs, stiff equations, and different methods for adjoint sensitivity calculations, this is a large generalization of the neural ODEs work and will allow researchers to better explore the problem domain.
(Note: If you are interested in this work and are an undergraduate or graduate student, we have Google Summer of Code projects available in this area. This pays quite well over the summer. Please join the Julia Slack and the #jsoc channel to discuss in more detail.)
- What do differential equations have to do with machine learning?
- What is the Neural Ordinary Differential Equation (ODE)?
- How do you solve an ODE?
- Let's Put an ODE Into a Neural Net Framework!
- Why is a full ODE solver suite necessary for doing this well?
- What kinds of differential equations are there?
- Implementing the Neural ODE layer in Julia
- Understanding the Neural ODE layer behavior by example
- The core technical challenge: backpropagation through differential equation solvers
- Conclusion
What do differential equations have to do with machine learning?
The first question someone not familiar with the field might ask is, why are differential equations important in this context? The simple answer is that a differential equation is a way to specify an arbitrary nonlinear transform by mathematically encoding prior structural assumptions.
Let's unpack that statement a bit. There are three common ways to define a nonlinear transform: direct modeling, machine learning, and differential equations. Directly writing down the nonlinear function only works if you know the exact functional form that relates the input to the output. However, in many cases, such exact relations are not known a priori. So how do you do nonlinear modeling if you don't know the nonlinearity?
One way to address this is to use machine learning. In a typical machine learning problem, you are given some input and you want to predict an output . This generation of a prediction from is a machine learning model (let's call it ). During training, we attempt to adjust the parameters of so that it generates accurate predictions. We can then use for inference (i.e., produce s for novel inputs ). This is just a nonlinear transformation . The reason is interesting is because its form is basic but adapts to the data itself. For example, a simple neural network (in design matrix form) with sigmoid activation functions is simply matrix multiplications followed by application of sigmoid functions. Specifically,
is a three-layer deep neural network, where are learnable parameters. You then choose such that reasonably fits the function you wanted it to fit. The theory and practice of machine learning confirms that this is a good way to learn nonlinearities. For example, the Universal Approximation Theorem states that, for enough layers or enough parameters (i.e. sufficiently large matrices), can approximate any nonlinear function sufficiently close (subject to common constraints).
So great, this always works! But it has some caveats, the main being that it has to learn everything about the nonlinear transform directly from the data. In many cases we do not know the full nonlinear equation, but we may know details about its structure. For example, the nonlinear function could be the population of rabbits in the forest, and we might know that their rate of births is dependent on the current population. Thus instead of starting from nothing, we may want to use this known a priori relation and a set of parameters that defines it. For the rabbits, let's say that we want to learn
In this case, we have prior knowledge of the rate of births being dependent on the current population. The way to mathematically state this structural assumption is via a differential equation. Here, what we are saying is that the birth rate of the rabbit population at a given time point increases when we have more rabbits. The simplest way of encoding that is
where is some learnable constant. If you know your calculus, the solution here is exponential growth from the starting point with a growth rate : . But notice that we didn't need to know the solution to the differential equation to validate the idea: we encoded the structure of the model and mathematics itself then outputs what the solution should be. Because of this, differential equations have been the tool of choice in most science. For example, physical laws tell you how electrical quantities emit forces (Maxwell's Equations). These are essentially equations of how things change and thus "where things will be" is the solution to a differential equation. But in recent decades this application has gone much further, with fields like systems biology learning about cellular interactions by encoding known biological structures and mathematically enumerating our assumptions or in targeted drug dosage through PK/PD modelling in systems pharmacology.
So as our machine learning models grow and are hungry for larger and larger amounts of data, differential equations have become an attractive option for specifying nonlinearities in a learnable (via the parameters) but constrained form. They are essentially a way of incorporating prior domain-specific knowledge of the structural relations between the inputs and outputs. Given this way of looking at the two, both methods trade off advantages and disadvantages, making them complementary tools for modeling. It seems like a clear next step in scientific practice to start putting them together in new and exciting ways!
What is the Neural Ordinary Differential Equation (ODE)?
The neural ordinary differential equation is one of many ways to put these two subjects together. The simplest way of explaining it is that, instead of learning the nonlinear transformation directly, we wish to learn the structures of the nonlinear transformation. Thus instead of doing , we put the machine learning model on the derivative, , and now solve the ODE. Why would you ever do this? Well, one motivation is that defining the model in this way and then solving the ODE using the simplest and most error prone method, the Euler method, what you get is equivalent to a residual neural network. The way the Euler method works is based on the fact that , thus
which implies that
This looks similar in structure to a ResNet, one of the most successful image processing models. The insight of the the Neural ODEs paper was that increasingly deep and powerful ResNet-like models effectively approximate a kind of "infinitely deep" model as each layer tends to zero. Rather than adding more layers, we can just model the differential equation directly and then solve it using a purpose-built ODE solver. Numerical ODE solvers are a science that goes all the way back to the first computers, and modern ones can adaptively choose step sizes and use high order approximations to drastically reduce the number of actual steps required. And as it turns out, this works well in practice, too.
How do you solve an ODE?
First, how do you numerically specify and solve an ODE? If you're new to solving ODEs, you may want to watch our video tutorial on solving ODEs in Julia and look through the ODE tutorial of the DifferentialEquations.jl documentation. The idea is that you define an ODEProblem via a derivative equation u'=f(u,p,t), and provide an initial condition u0, and a timespan tspan to solve over, and specify the parameters p.
For example, the Lotka-Volterra equations describe the dynamics of the population of rabbits and wolves. They can be written as:
and encoded in Julia like:
using DifferentialEquations
function lotka_volterra(du,u,p,t)
x, y = u
α, β, δ, γ = p
du[1] = dx = α*x - β*x*y
du[2] = dy = -δ*y + γ*x*y
end
u0 = [1.0,1.0]
tspan = (0.0,10.0)
p = [1.5,1.0,3.0,1.0]
prob = ODEProblem(lotka_volterra,u0,tspan,p)Then to solve the differential equations, you can simply call solve on the prob:
sol = solve(prob)
using Plots
plot(sol)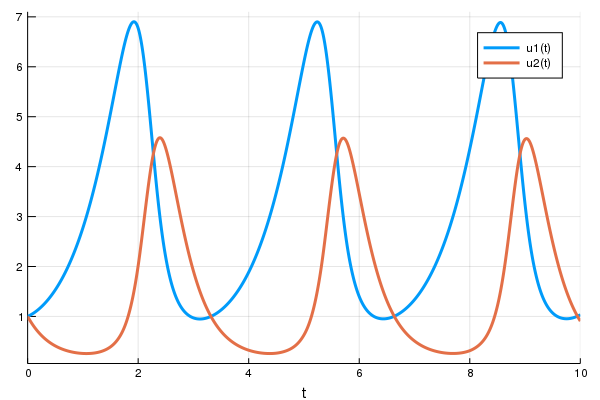
One last thing to note is that we can make our initial condition (u0) and time spans (tspans) to be functions of the parameters (the elements of p). For example, we can define the ODEProblem:
u0_f(p,t0) = [p[2],p[4]]
tspan_f(p) = (0.0,10*p[4])
p = [1.5,1.0,3.0,1.0]
prob = ODEProblem(lotka_volterra,u0_f,tspan_f,p)In this form, everything about the problem is determined by the parameter vector (p, referred to as θ in associated literature). The utility of this will be seen later.
DifferentialEquations.jl has many powerful options for customising things like accuracy, tolerances, solver methods, events and more; check out the docs for more details on how to use it in more advanced ways.
Let's Put an ODE Into a Neural Net Framework!
To understand embedding an ODE into a neural network, let's look at what a neural network layer actually is. A layer is really just a differentiable function which takes in a vector of size n and spits out a new vector of size m. That's it! Layers have traditionally been simple functions like matrix multiply, but in the spirit of differentiable programming people are increasingly experimenting with much more complex functions, such as ray tracers and physics engines.
Turns out that differential equations solvers fit this framework, too: A solve takes in some vector p (which might include parameters like the initial starting point), and outputs some new vector, the solution. Moreover it's differentiable, which means we can put it straight into a larger differentiable program. This larger program can happily include neural networks, and we can keep using standard optimisation techniques like ADAM to optimise their weights.
DiffEqFlux.jl makes it convenient to do just this; let's take it for a spin. We'll start by solving an equation as before, without gradients.
p = [1.5,1.0,3.0,1.0]
prob = ODEProblem(lotka_volterra,u0,tspan,p)
sol = solve(prob,Tsit5(),saveat=0.1)
A = sol[1,:] # length 101 vectorLet's plot (t,A) over the ODE's solution to see what we got:
plot(sol)
t = 0:0.1:10.0
scatter!(t,A)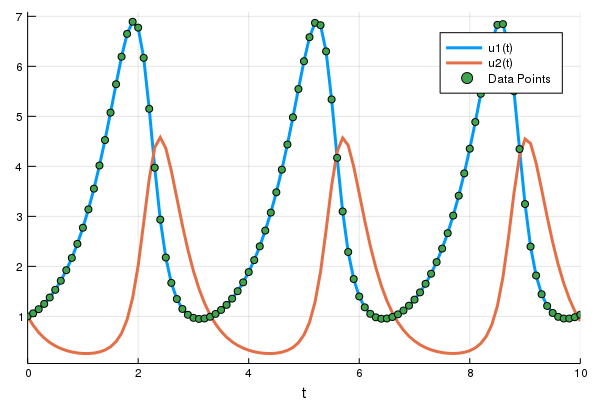
The nice thing about solve is that it takes care of the type handling necessary to make it compatible with the neural network framework (here Flux). To show this, let's define a neural network with the function as our single layer, and then a loss function that is the squared distance of the output values from 1. In Flux, this looks like:
using Flux, DiffEqFlux
p = [2.2, 1.0, 2.0, 0.4] # Initial Parameter Vector
params = Flux.params(p)
function predict_rd() # Our 1-layer "neural network"
solve(prob,Tsit5(),p=p,saveat=0.1)[1,:] # override with new parameters
end
loss_rd() = sum(abs2,x-1 for x in predict_rd()) # loss functionNow we tell Flux to train the neural network by running a 100 epoch to minimize our loss function (loss_rd()) and thus obtain the optimized parameters:
data = Iterators.repeated((), 100)
opt = ADAM(0.1)
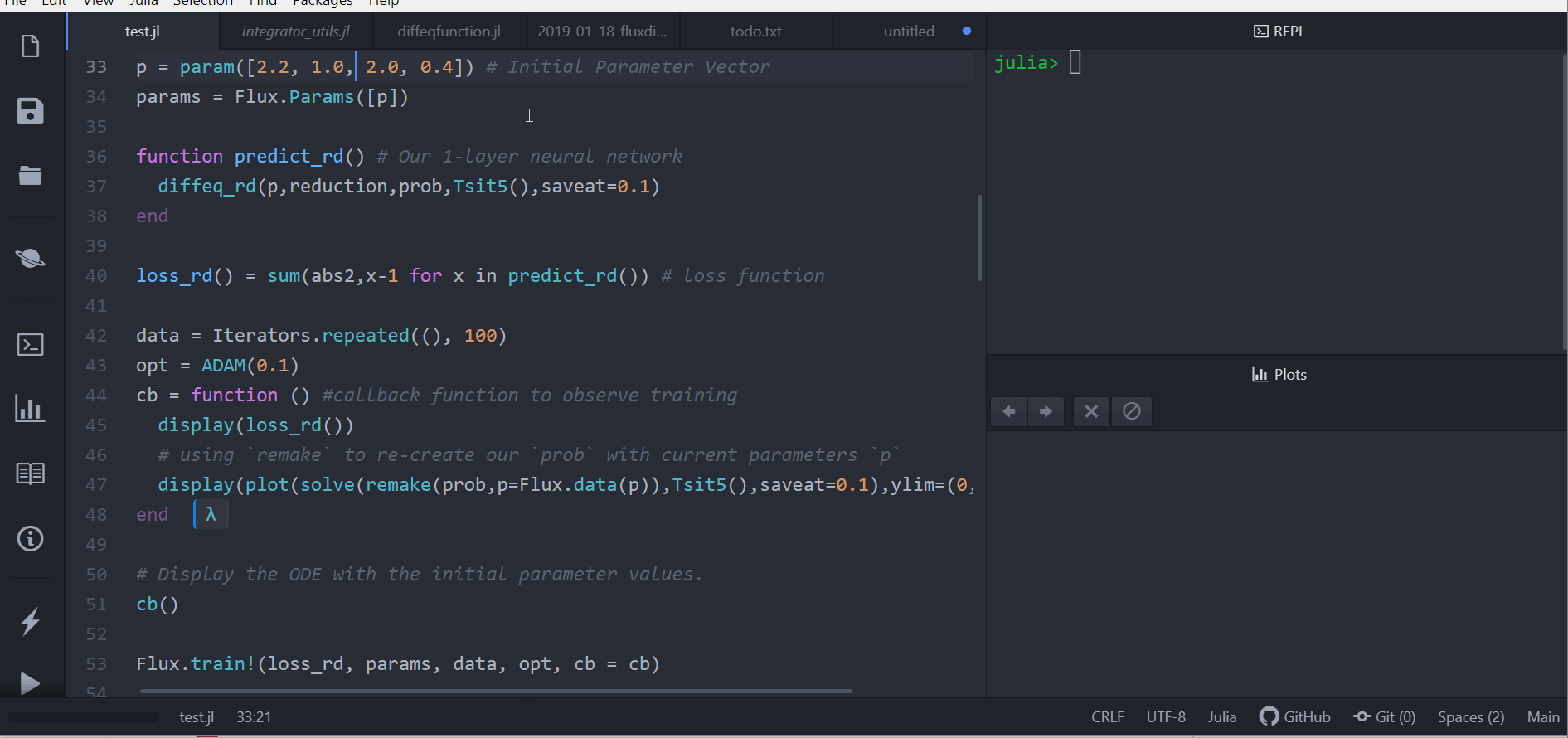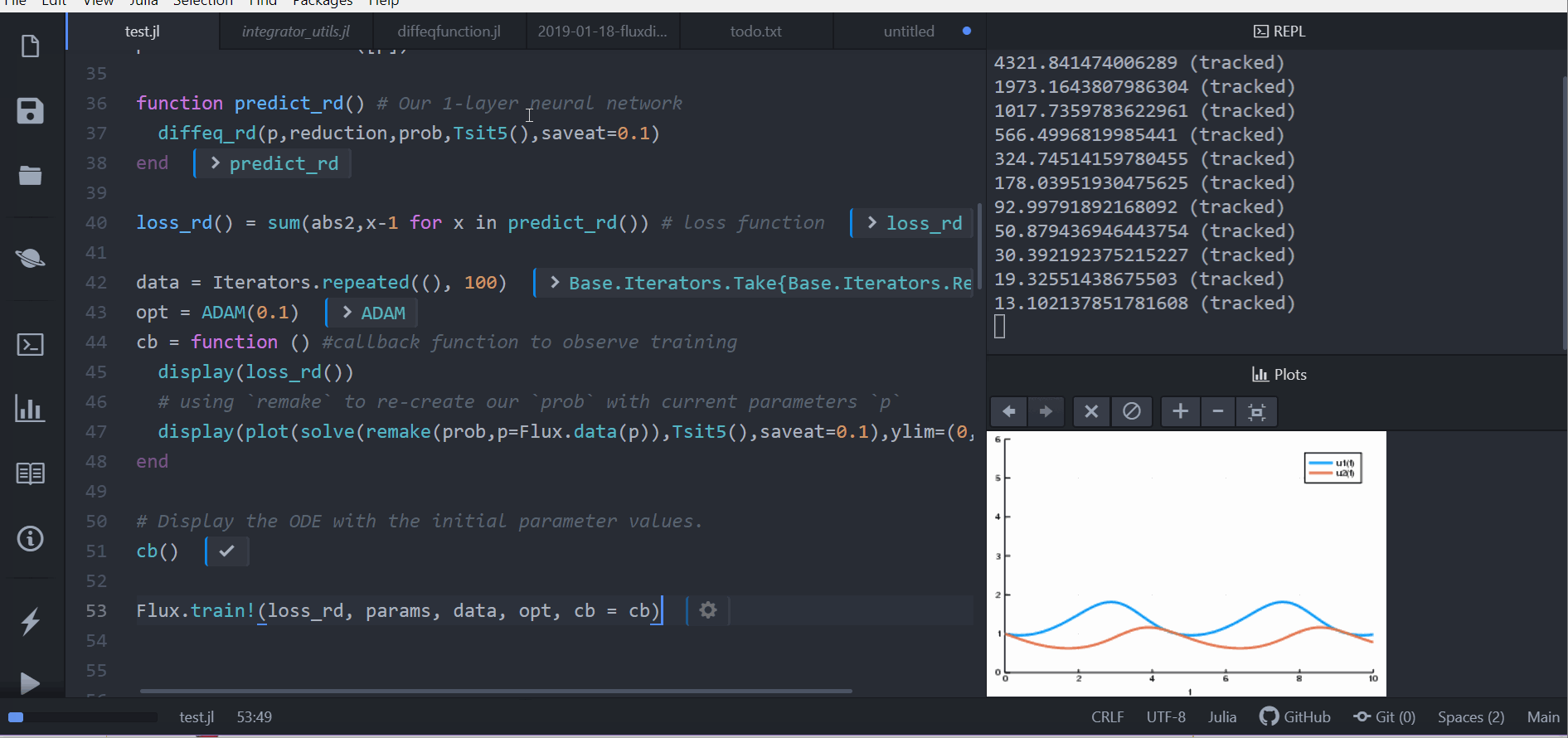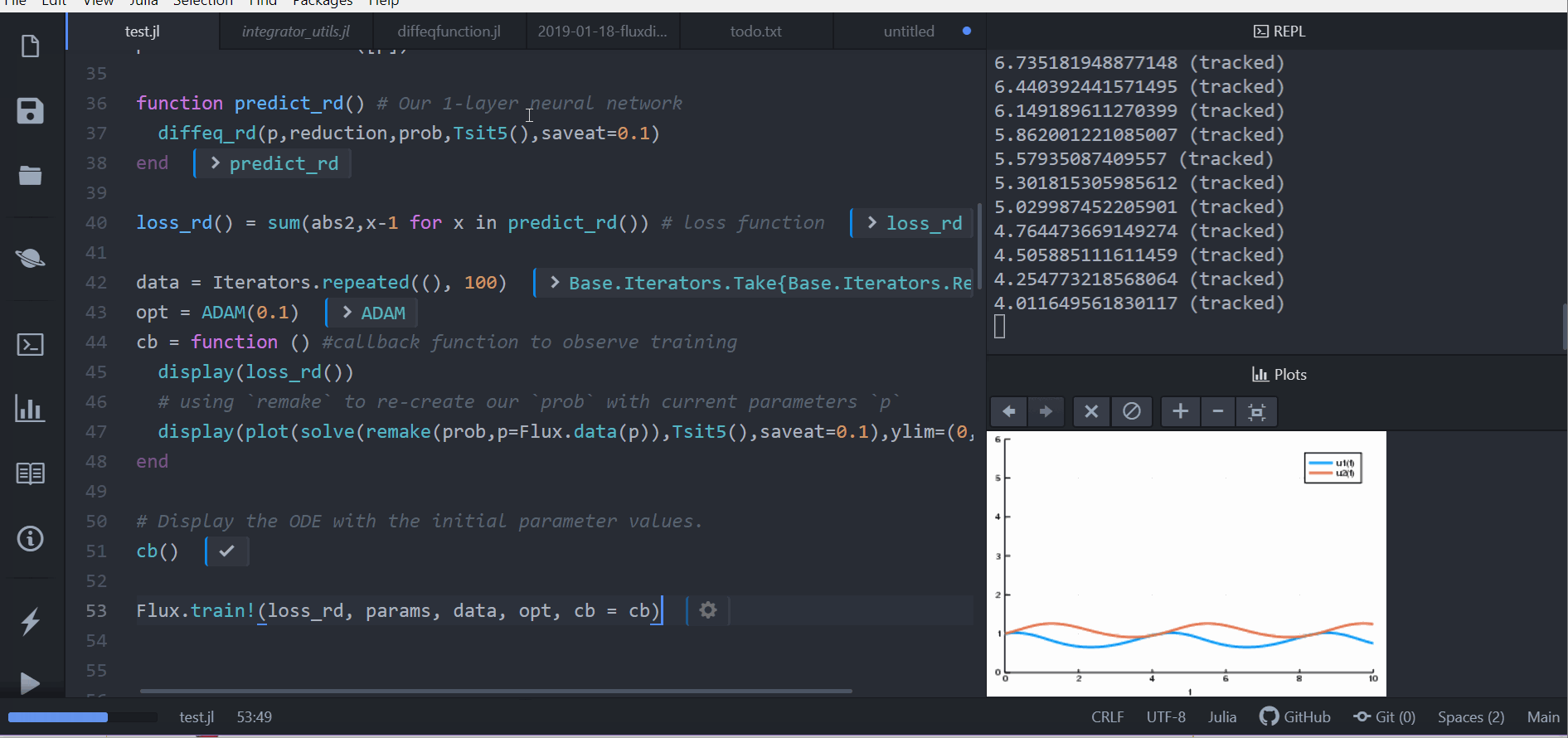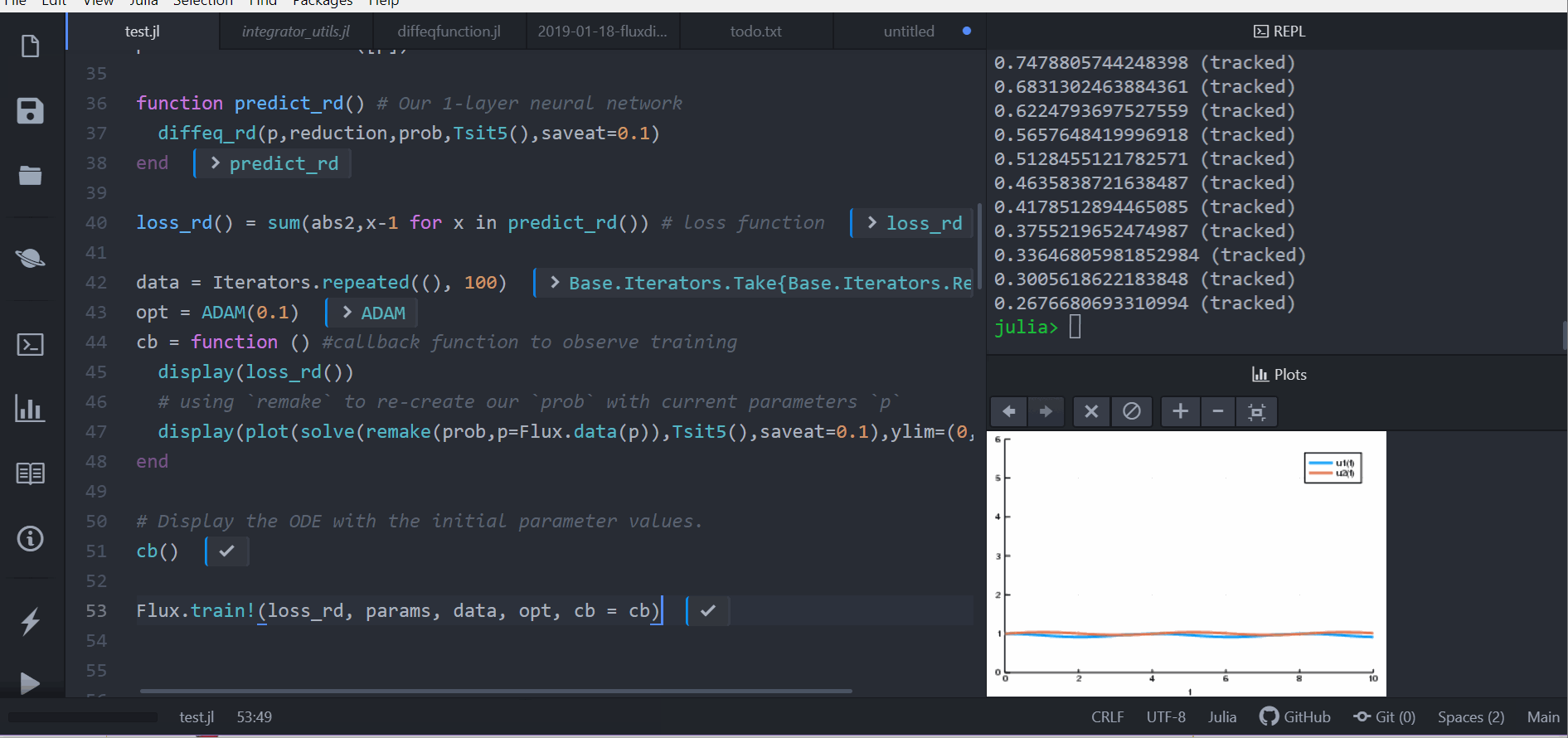
cb = function () #callback function to observe training
display(loss_rd())
# using `remake` to re-create our `prob` with current parameters `p`
display(plot(solve(remake(prob,p=p),Tsit5(),saveat=0.1),ylim=(0,6)))
end
# Display the ODE with the initial parameter values.
cb()
Flux.train!(loss_rd, params, data, opt, cb = cb)The result of this is the animation shown at the top. This code can be found in the model-zoo
Flux finds the parameters of the neural network (p) which minimize the cost function, i.e. it trains the neural network: it just so happens that the forward pass of the neural network includes solving an ODE. Since our cost function put a penalty whenever the number of rabbits was far from 1, our neural network found parameters where our population of rabbits and wolves are both constant 1.
Now that we have solving ODEs as just a layer, we can add it anywhere. For example, the multilayer perceptron is written in Flux as
m = Chain(
Dense(28^2, 32, relu),
Dense(32, 10),
softmax)and if we had an appropriate ODE which took a parameter vector of the right size, we can stick it right in there:
m = Chain(
Dense(28^2, 32, relu),
# this would require an ODE of 32 parameters
p -> solve(prob,Tsit5(),p=p,saveat=0.1)[1,:],
Dense(32, 10),
softmax)or we can stick it into a convolutional neural network, where the previous layers define the initial condition for the ODE:
m = Chain(
Conv((2,2), 1=>16, relu),
x -> maxpool(x, (2,2)),
Conv((2,2), 16=>8, relu),
x -> maxpool(x, (2,2)),
x -> reshape(x, :, size(x, 4)),
x -> solve(prob,Tsit5(),u0=x,saveat=0.1)[1,:],
Dense(288, 10), softmax) |> gpuAs long as you can write down the forward pass, we can take any parameterised, differentiable program and optimise it. The world is your oyster.
Why is a full ODE solver suite necessary for doing this well?
Where we have combined an existing solver suite and deep learning library, the excellent torchdiffeq project takes an alternative approach, instead implementing solver methods directly in PyTorch, including an adaptive Runge Kutta 4-5 (dopri5) and an Adams-Bashforth-Moulton method (adams). However, while their approach is very effective for certain kinds of models, not having access to a full solver suite is limiting.
Consider the following example, the ROBER ODE. The most well-tested (and optimized) implementation of an Adams-Bashforth-Moulton method is the CVODE integrator in the C++ package SUNDIALS (a derivative of the classic LSODE). Let's use DifferentialEquations.jl to call CVODE with its Adams method and have it solve the ODE for us:
using ParameterizedFunctions # required for the `@ode_def` macro
using Sundials
rober = @ode_def Rober begin
dy₁ = -k₁*y₁+k₃*y₂*y₃
dy₂ = k₁*y₁-k₂*y₂^2-k₃*y₂*y₃
dy₃ = k₂*y₂^2
end k₁ k₂ k₃
prob = ODEProblem(rober,[1.0;0.0;0.0],(0.0,1e11),(0.04,3e7,1e4))
solve(prob,CVODE_Adams())(For those familiar with solving ODEs in MATLAB, this is similar to ode113)
Both this and the dopri method from Ernst Hairer's Fortran Suite stall and fail to solve the equation. This happens because the ODE is stiff, and thus methods with "smaller stability regions" will not be able to solve it appropriately (for more details, I suggest reading Hairer's Solving Ordinary Differential Equations II). On the other hand KenCarp4() to this problem, the equation is solved in a blink of an eye:
sol = solve(prob,KenCarp4())
using Plots
plot(sol,xscale=:log10,tspan=(0.1,1e11))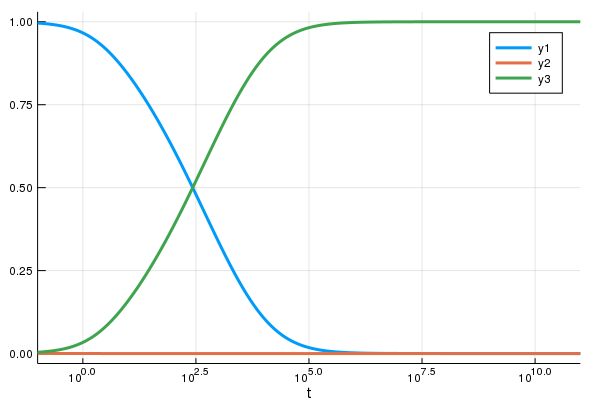
This is just one example of subtlety in integration: Stabilizing explicit methods via PI-adaptive controllers, step prediction in implicit solvers, etc. are all intricate details that take a lot of time and testing to become efficient and robust. Different problems require different methods: Symplectic integrators are required to adequately handle physical many problems without drift, and tools like IMEX integrators are required to handle ODEs which come from partial differential equations. Building a production-quality solver is thus an enormous undertaking and relatively few exist.
Rather than building an ML-specific solver suite in parallel to one suitable for scientific computing, in Julia they are one and the same, meaning you can take advantage of all of these methods today.
What kinds of differential equations are there?
Ordinary differential equations are only one kind of differential equation. There are many additional features you can add to the structure of a differential equation. For example, the amount of bunnies in the future isn't dependent on the number of bunnies right now because it takes a non-zero amount of time for a parent to come to term after a child is incepted. Thus the birth rate of bunnies is actually due to the amount of bunnies in the past. Using a lag term in a differential equation's derivative makes this equation known as a delay differential equation (DDE). Since DifferentialEquations.jl handles DDEs through the same interface as ODEs, it can be used as a layer in Flux as well. Here's an example:
function delay_lotka_volterra(du,u,h,p,t)
x, y = u
α, β, δ, γ = p
du[1] = dx = (α - β*y)*h(p,t-0.1)[1]
du[2] = dy = (δ*x - γ)*y
end
h(p,t) = ones(eltype(p),2)
prob = DDEProblem(delay_lotka_volterra,[1.0,1.0],h,(0.0,10.0),constant_lags=[0.1])
p = [2.2, 1.0, 2.0, 0.4]
params = Flux.params(p)
using SciMLSensitivity
function predict_rd_dde()
solve(prob,MethodOfSteps(Tsit5()),p=p,sensealg=TrackerAdjoint(),saveat=0.1)[1,:]
end
loss_rd_dde() = sum(abs2,x-1 for x in predict_rd_dde())
loss_rd_dde()The full code for this example, including generating an animation, can be found in the model-zoo
Additionally we can add randomness to our differential equation to simulate how random events can cause extra births or more deaths than expected. This kind of equation is known as a stochastic differential equation (SDE). Since DifferentialEquations.jl handles SDEs (and is currently the only library with adaptive stiff and non-stiff SDE integrators), these can be handled as a layer in Flux similarly. Here's a neural net layer with an SDE:
function lotka_volterra_noise(du,u,p,t)
du[1] = 0.1u[1]
du[2] = 0.1u[2]
end
prob = SDEProblem(lotka_volterra,lotka_volterra_noise,[1.0,1.0],(0.0,5.0))
p = [2.2, 1.0, 2.0, 0.4]
params = Flux.params(p)
function predict_sde()
solve(prob,SOSRI(),p=p,sensealg=TrackerAdjoint(),saveat=0.1,
abstol=1e-1,reltol=1e-1)[1,:]
end
loss_rd_sde() = sum(abs2,x-1 for x in predict_sde())
loss_rd_sde()And we can train the neural net to watch it in action and find parameters to make the amount of bunnies close to constant:
data = Iterators.repeated((), 100)
opt = ADAM(0.1)
cb = function ()
display(loss_rd_sde())
display(plot(solve(remake(prob,p=p),SOSRI(),saveat=0.1),ylim=(0,6)))
end
# Display the ODE with the current parameter values.
cb()
Flux.train!(loss_rd_sde, params, data, opt, cb = cb)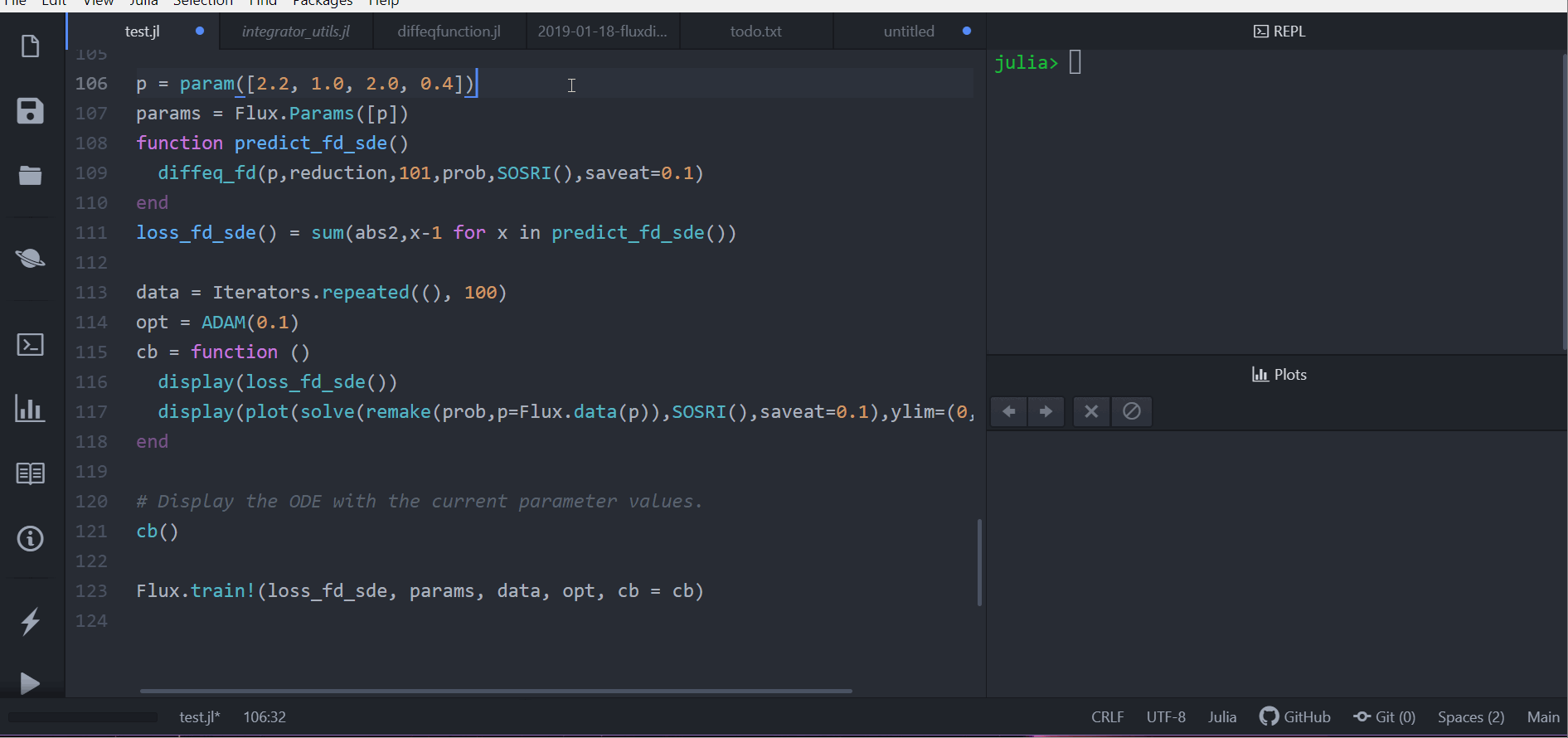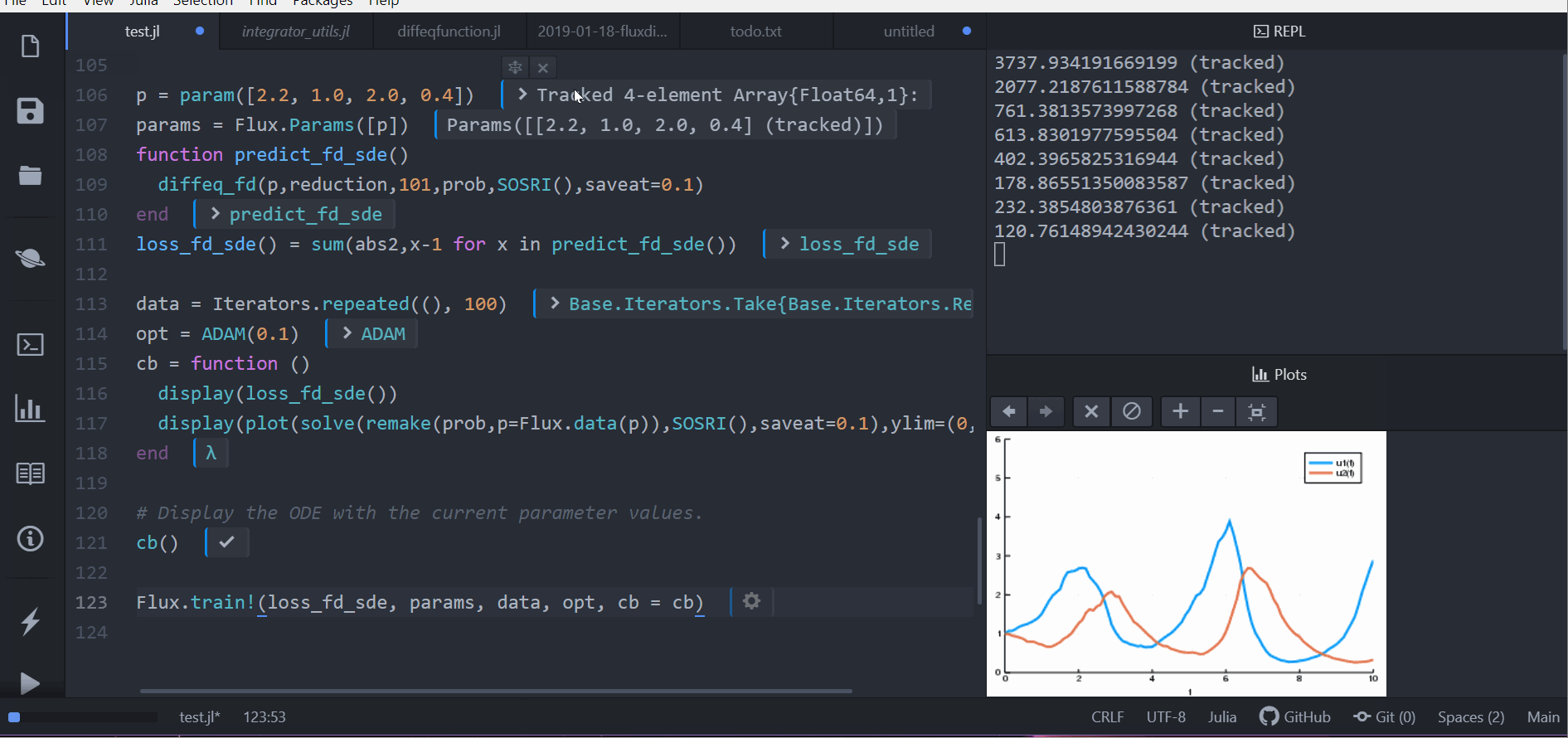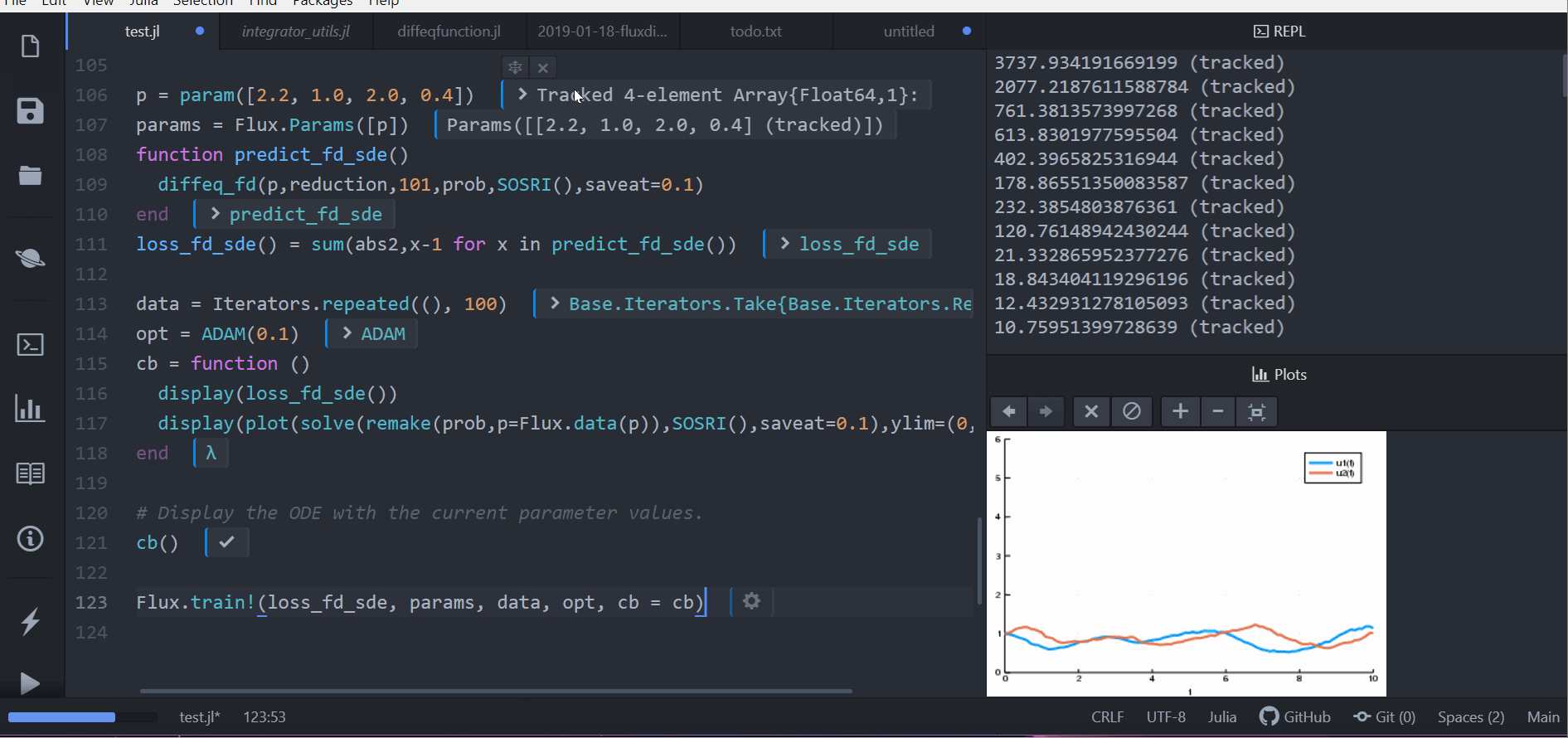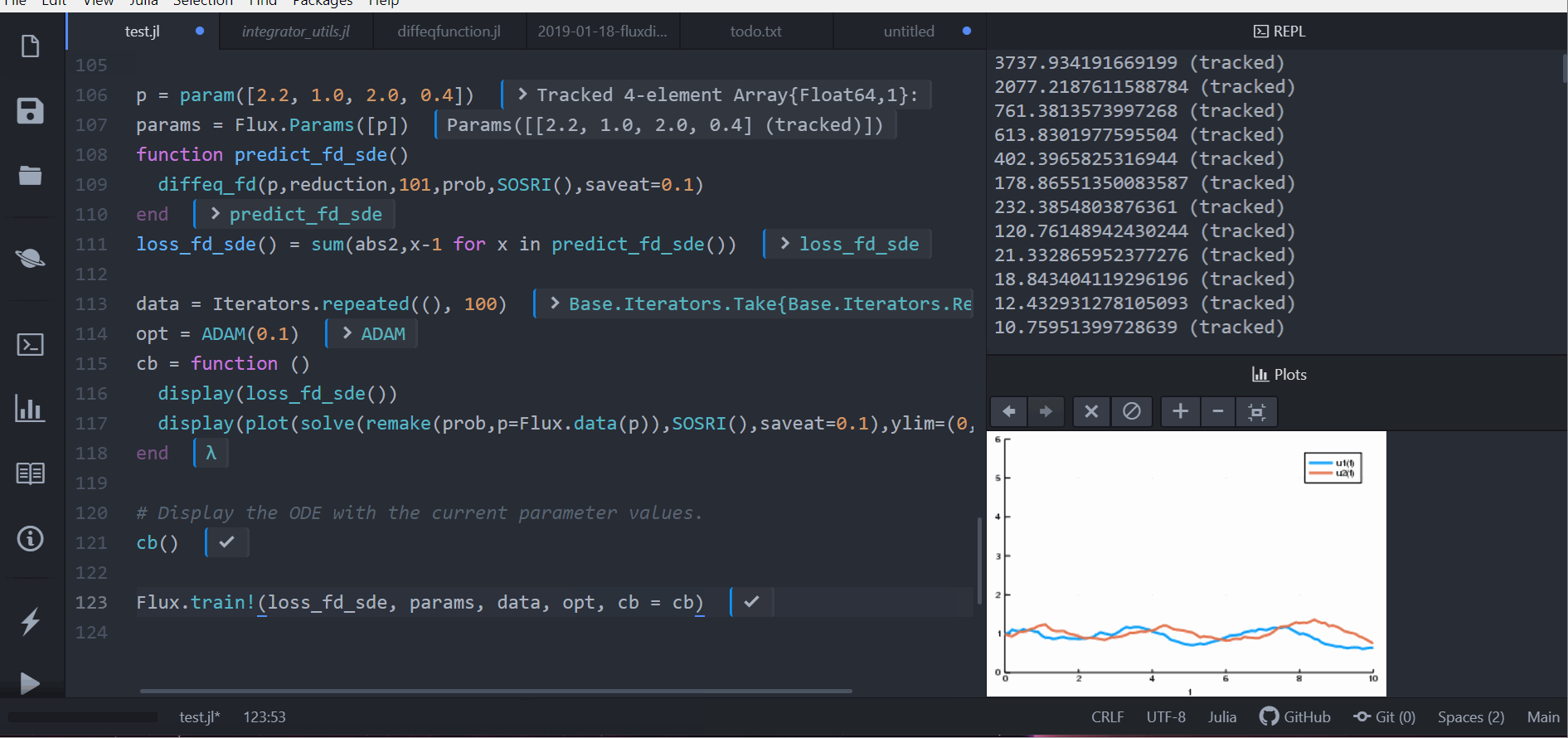
This code can be found in the model-zoo
And we can keep going. There are differential equations which are piecewise constant used in biological simulations, or jump diffusion equations from financial models, and the solvers map right over to the Flux neural network framework through DiffEqFlux.jl. DiffEqFlux.jl uses only around ~100 lines of code to pull this all off.
Implementing the Neural ODE layer in Julia
Let's go all the way back for a second and now implement the neural ODE layer in Julia. Remember that this is simply an ODE where the derivative function is defined by a neural network itself. To do this, let's first define the neural net for the derivative. In Flux, we can define a multilayer perceptron with 1 hidden layer and a tanh activation function like:
dudt = Chain(Dense(2,50,tanh),Dense(50,2))To define a NeuralODE layer, we then just need to give it a timespan and use the NeuralODE function:
tspan = (0.0f0,25.0f0)
node = NeuralODE(dudt,tspan,Tsit5(),saveat=0.1)As a side note, to run this on the GPU, it is sufficient to make the initial condition and neural network be on the GPU. This will cause the entire ODE solver's internal operations to take place on the GPU without extra data transfers in the integration scheme. This looks like:
node = NeuralODE(gpu(dudt),tspan,Tsit5(),saveat=0.1)Understanding the Neural ODE layer behavior by example
Now let's use the neural ODE layer in an example to find out what it means. First, let's generate a time series of an ODE at evenly spaced time points. We'll use the test equation from the Neural ODE paper.
u0 = Float32[2.; 0.]
datasize = 30
tspan = (0.0f0,1.5f0)
function trueODEfunc(du,u,p,t)
true_A = [-0.1 2.0; -2.0 -0.1]
du .= ((u.^3)'true_A)'
end
t = range(tspan[1],tspan[2],length=datasize)
prob = ODEProblem(trueODEfunc,u0,tspan)
ode_data = Array(solve(prob,Tsit5(),saveat=t))Now let's pit a neural ODE against this data. To do so, we will define a single layer neural network which just has the same neural ODE as before (but lower the tolerances to help it converge closer, makes for a better animation!):
dudt = Chain(x -> x.^3,
Dense(2,50,tanh),
Dense(50,2))
n_ode = NeuralODE(dudt,tspan,Tsit5(),saveat=t,reltol=1e-7,abstol=1e-9)
ps = Flux.params(n_ode)Notice that the NeuralODE has the same timespan and saveat as the solution that generated the data. This means that given an x (and initial value), it will generate a guess for what it thinks the time series will be where the dynamics (the structure) is predicted by the internal neural network. Let's see what time series it gives before we train the network. Since the ODE has two-dependent variables, we will simplify the plot by only showing the first. The code for the plot is:
pred = n_ode(u0) # Get the prediction using the correct initial condition
scatter(t,ode_data[1,:],label="data")
scatter!(t,pred[1,:],label="prediction")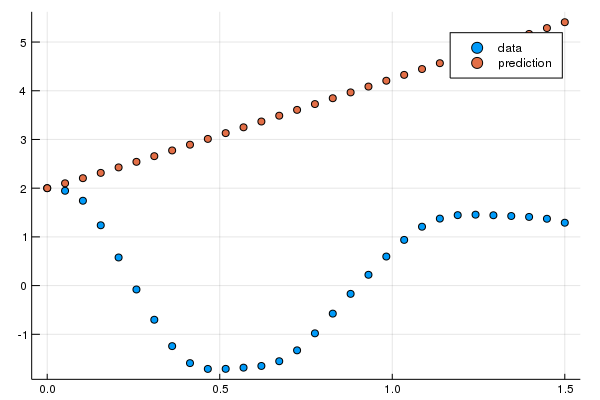
But now let's train our neural network. To do so, define a prediction function like before, and then define a loss between our prediction and data:
function predict_n_ode()
n_ode(u0)
end
loss_n_ode() = sum(abs2,ode_data .- predict_n_ode())And now we train the neural network and watch as it learns how to predict our time series:
data = Iterators.repeated((), 1000)
opt = ADAM(0.1)
cb = function () #callback function to observe training
display(loss_n_ode())
# plot current prediction against data
cur_pred = predict_n_ode()
pl = scatter(t,ode_data[1,:],label="data")
scatter!(pl,t,cur_pred[1,:],label="prediction")
display(plot(pl))
end
# Display the ODE with the initial parameter values.
cb()
Flux.train!(loss_n_ode, ps, data, opt, cb = cb)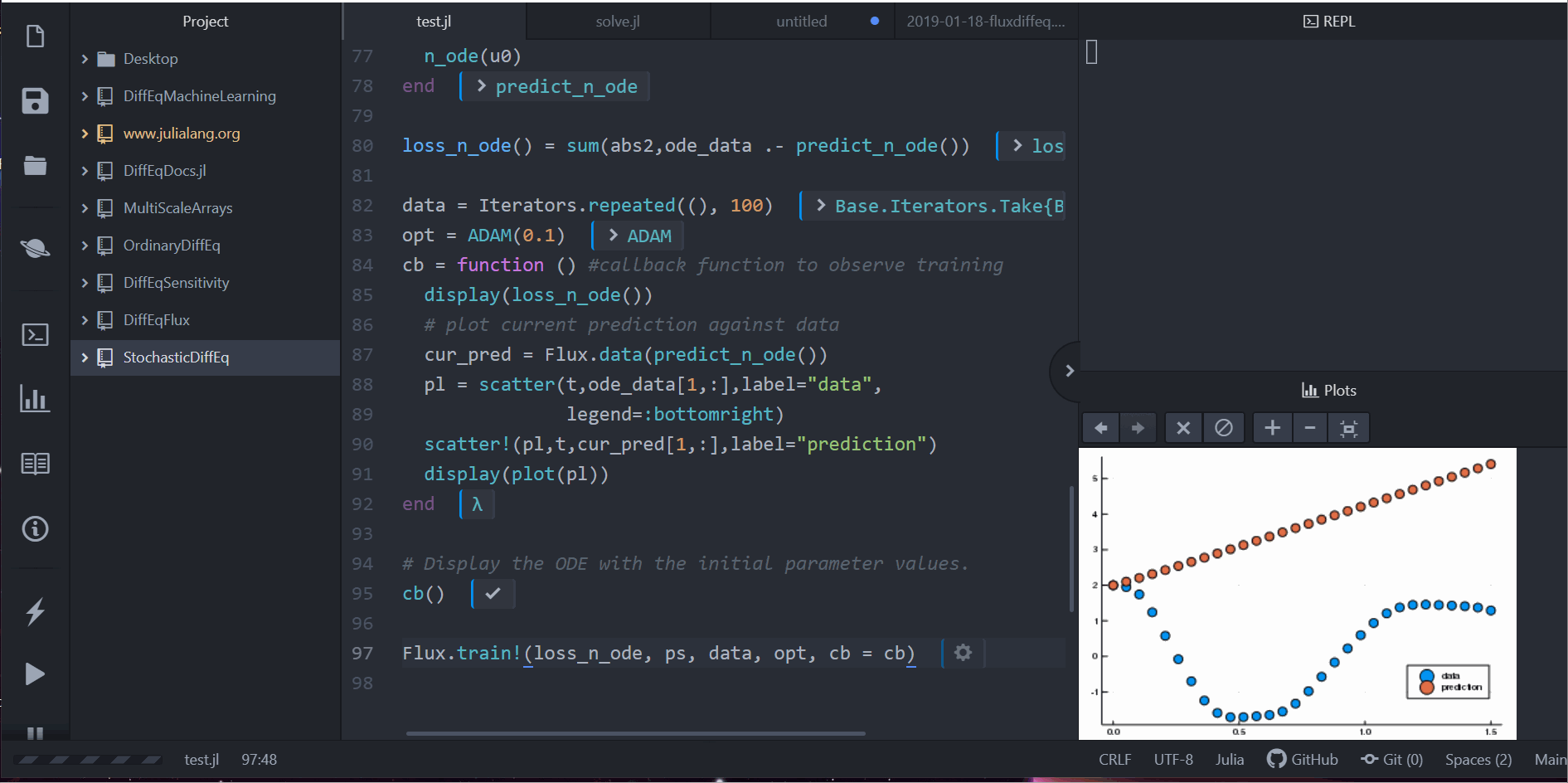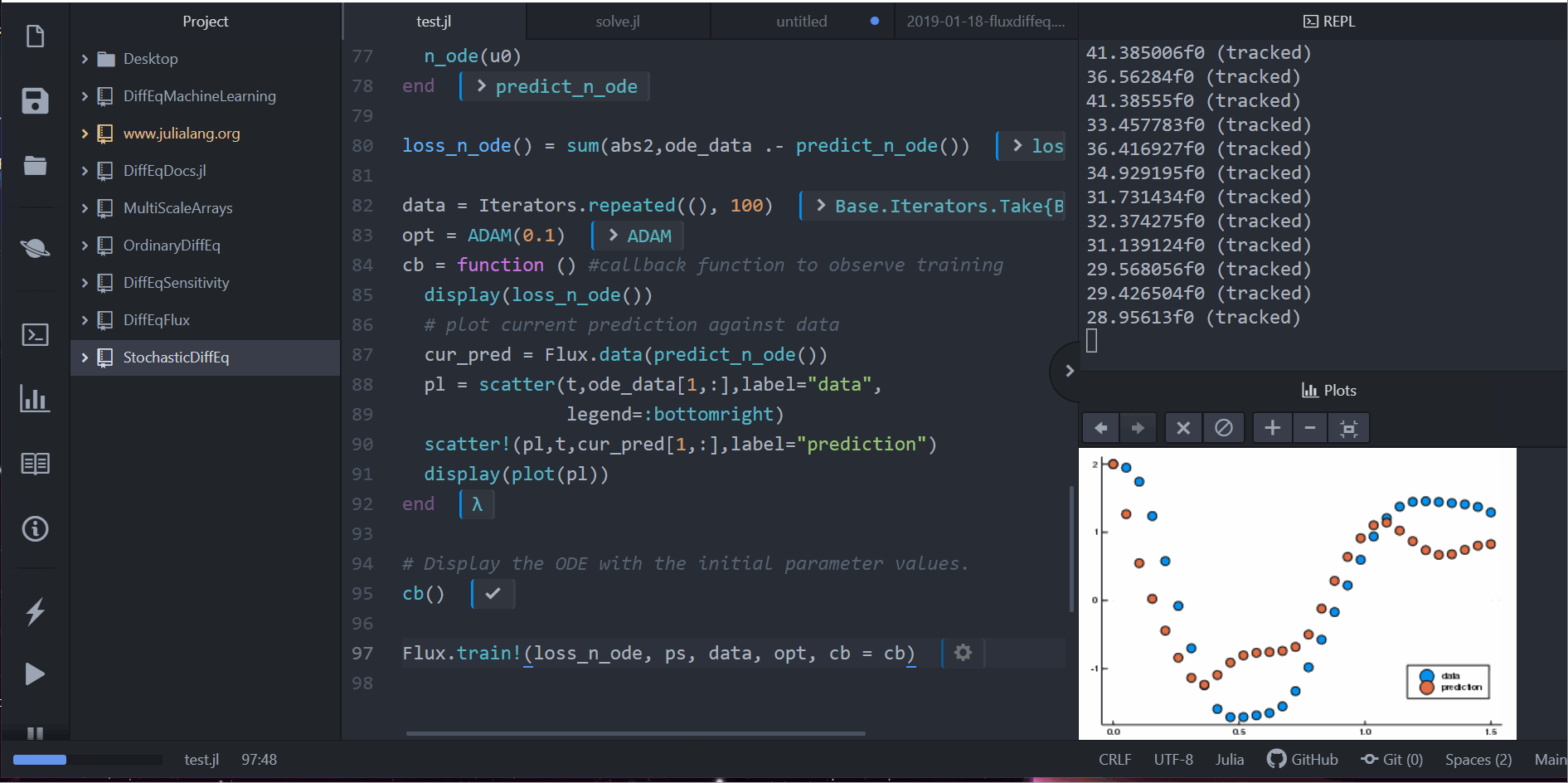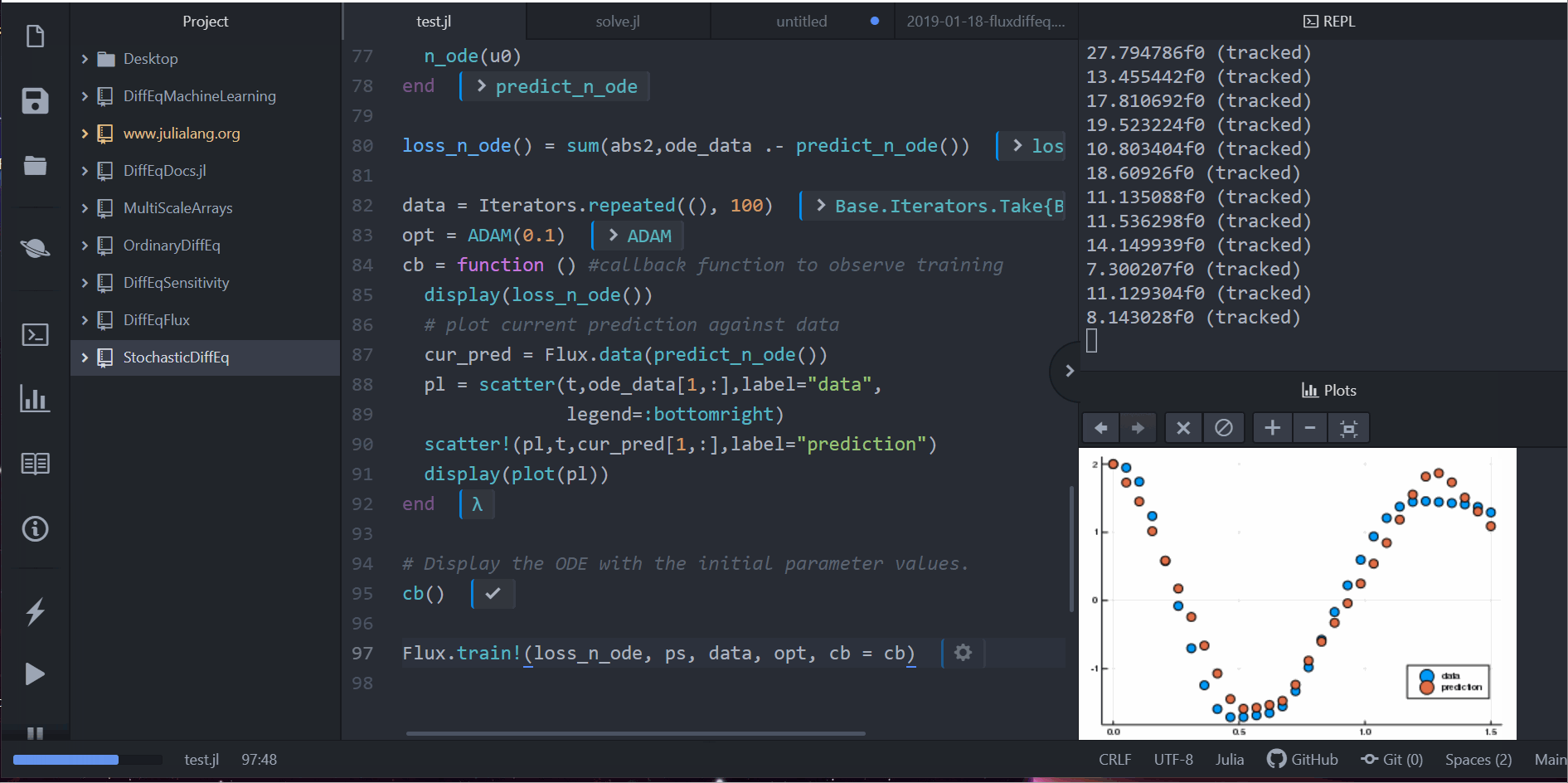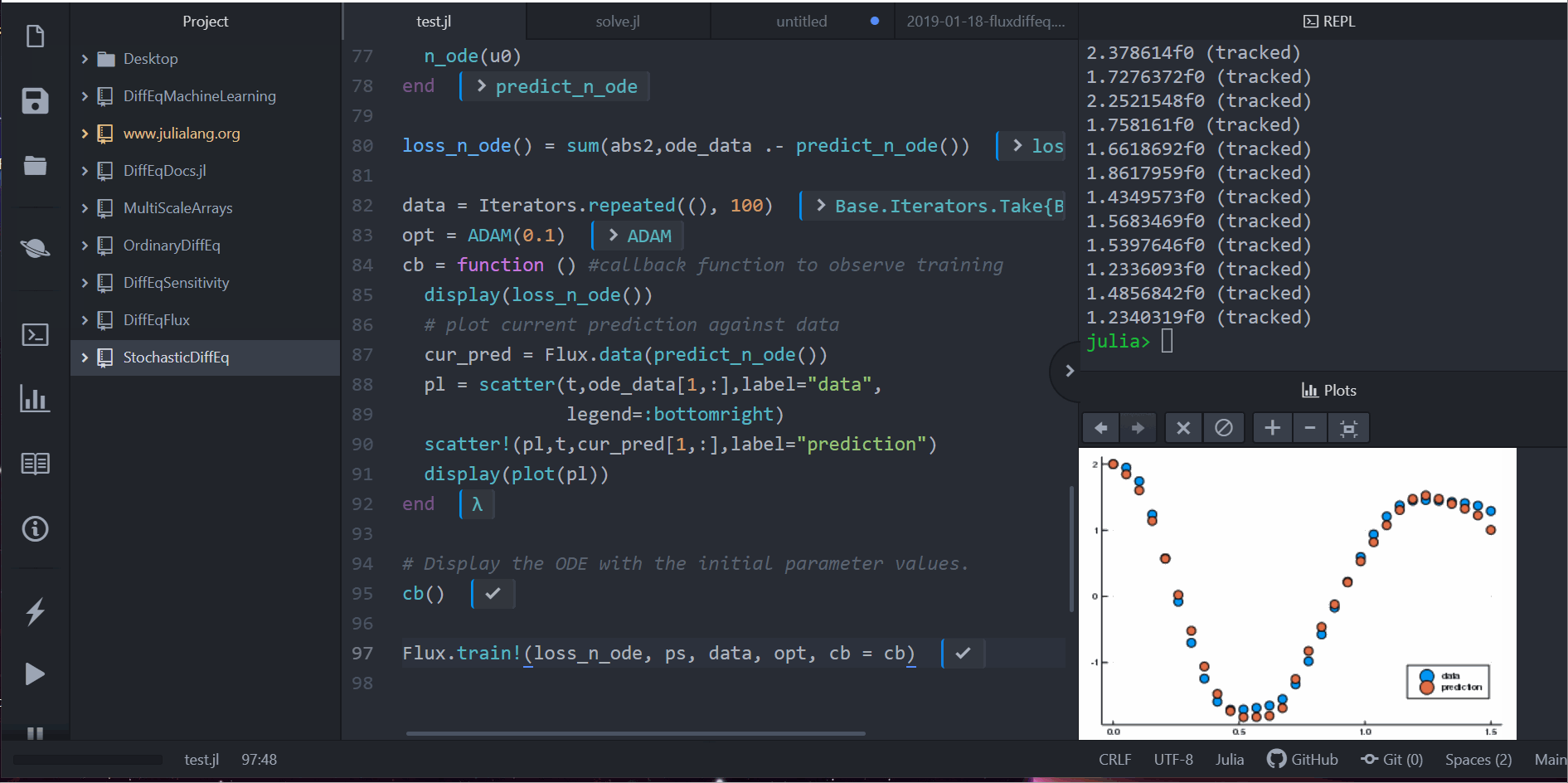
This code can be found in the model-zoo
Notice that we are not learning a solution to the ODE. Instead, what we are learning is the tiny ODE system from which the ODE solution is generated. I.e., the neural network inside the neural_ode layer learns this function:
u' = A*u^3Thus it learned a compact representation of how the time series works, and it can easily extrapolate to what would happen with different starting conditions. Not only that, it's a very flexible method for learning such representations. For example, if your data is unevenly spaced at time points t, just pass in saveat=t and the ODE solver takes care of it.
As you could probably guess by now, the DiffEqFlux.jl has all kinds of extra related goodies like Neural SDEs (NeuralSDE) for you to explore in your applications.
The core technical challenge: backpropagation through differential equation solvers
Let's end by explaining the technical issue that needed a solution to make this all possible. The core to any neural network framework is the ability to backpropagate derivatives in order to calculate the gradient of the loss function with respect to the network's parameters. Thus if we stick an ODE solver as a layer in a neural network, we need to backpropagate through it.
There are multiple ways to do this. The most common is known as (adjoint) sensitivity analysis. Sensitivity analysis defines a new ODE whose solution gives the gradients to the cost function w.r.t. the parameters, and solves this secondary ODE. This is the method discussed in the neural ordinary differential equations paper, but actually dates back much further, and popular ODE solver frameworks like FATODE, CASADI, and CVODES have been available with this adjoint method for a long time (CVODES came out in 2005!). DifferentialEquations.jl has sensitivity analysis implemented too
The efficiency problem with adjoint sensitivity analysis methods is that they require multiple forward solutions of the ODE. As you would expect, this is very costly. Methods like the checkpointing scheme in CVODES reduce the cost by saving closer time points to make the forward solutions shorter at the cost of using more memory. The method in the neural ordinary differential equations paper tries to eliminate the need for these forward solutions by doing a backwards solution of the ODE itself along with the adjoints. The issue with this is that this method implicitly makes the assumption that the ODE integrator is reversible. Sadly, there are no reversible adaptive integrators for first-order ODEs, so with no ODE solver method is this guaranteed to work. For example, here's a quick equation where a backwards solution to the ODE using the Adams method from the paper has >1700% error in its final point, even with solver tolerances of 1e-12:
using Sundials, DiffEqBase
function lorenz(du,u,p,t)
du[1] = 10.0*(u[2]-u[1])
du[2] = u[1]*(28.0-u[3]) - u[2]
du[3] = u[1]*u[2] - (8/3)*u[3]
end
u0 = [1.0;0.0;0.0]
tspan = (0.0,100.0)
prob = ODEProblem(lorenz,u0,tspan)
sol = solve(prob,CVODE_Adams(),reltol=1e-12,abstol=1e-12)
prob2 = ODEProblem(lorenz,sol[end],(100.0,0.0))
sol = solve(prob,CVODE_Adams(),reltol=1e-12,abstol=1e-12)
@show sol[end]-u0 #[-17.5445, -14.7706, 39.7985](Here we once again use the CVODE C++ solvers from SUNDIALS since they are a close match to the SciPy integrators used in the neural ODE paper.)
This inaccuracy is the reason why the method from the neural ODE paper is not implemented in software suites, but it once again highlights a detail. Not all ODEs will have a large error due to this issue. And for ODEs where it's not a problem, this will be the most efficient way to do adjoint sensitivity analysis. And this method only applies to ODEs. Not only that, it doesn't even apply to all ODEs. For example, ODEs with discontinuities (events) are excluded by the assumptions of the derivation. Thus once again we arrive at the conclusion that one method is not enough.
In DifferentialEquations.jl have implemented many different methods for computing the derivatives of differential equations with respect to parameters. We have a recent preprint detailing some of these results. One of the things we have found is that direct use of automatic differentiation can be one of the most efficient and flexible methods. Julia's ForwardDiff.jl, Flux, and ReverseDiff.jl can directly be applied to perform automatic differentiation on the native Julia differential equation solvers themselves, and this can increase performance while giving new features. Our findings show that forward-mode automatic differentiation is fastest when there are less than 100 parameters in the differential equations, and that for >100 number of parameters adjoint sensitivity analysis is the most efficient. Even then, we have good reason to believe that the next generation reverse-mode automatic differentiation via source-to-source AD, Zygote.jl, will be more efficient than all of the adjoint sensitivity implementations for large numbers of parameters.
Altogether, being able to switch between different gradient methods without changing the rest of your code is crucial for having a scalable, optimized, and maintainable framework for integrating differential equations and neural networks. And this is precisely what DiffEqFlux.jl gives the user direct access to. There are three functions with a similar API:
diffeq_rduses Flux's reverse-mode AD through the differential equation solver.diffeq_fduses ForwardDiff.jl's forward-mode AD through the differential equation solver.diffeq_adjointuses adjoint sensitivity analysis to "backprop the ODE solver"
Therefore, to switch from a reverse-mode AD layer to a forward-mode AD layer, one simply has to change a single character. Since Julia-based automatic differentiation works on Julia code, the native Julia differential equation solvers will continue to benefit from advances in this field.
Conclusion
Machine learning and differential equations are destined to come together due to their complementary ways of describing a nonlinear world. In the Julia ecosystem we have merged the differential equation and deep learning packages in such a way that new independent developments in the two domains can directly be used together. We are only beginning to understand the possibilities that have opened up with this software. We hope that future blog posts will detail some of the cool applications which mix the two disciplines, such as embedding our coming pharmacometric simulation engine PuMaS.jl into the deep learning framework. With access to the full range of solvers for ODEs, SDEs, DAEs, DDEs, PDEs, discrete stochastic equations, and more, we are interested to see what kinds of next generation neural networks you will build with Julia.
Note: a citable version of this post is published on Arxiv.
@article{DBLP:journals/corr/abs-1902-02376,
author = {Christopher Rackauckas and
Mike Innes and
Yingbo Ma and
Jesse Bettencourt and
Lyndon White and
Vaibhav Dixit},
title = {DiffEqFlux.jl - {A} Julia Library for Neural Differential Equations},
journal = {CoRR},
volume = {abs/1902.02376},
year = {2019},
url = {https://arxiv.org/abs/1902.02376},
archivePrefix = {arXiv},
eprint = {1902.02376},
timestamp = {Tue, 21 May 2019 18:03:36 +0200},
biburl = {https://dblp.org/rec/bib/journals/corr/abs-1902-02376},
bibsource = {dblp computer science bibliography, https://dblp.org}
}