Julia version 1.6 has been released. Most Julia releases are timed and hence not planned around specific features, but this release was an exception since it is likely to become the next long-term support (LTS) release of Julia. Because of this, we took extra time developing the release to make sure that features which are needed for the future health of the ecosystem made it into the release. Also, the release was tested for regressions against all registered open source packages and issues were tracked down and fixed. The final decision about whether Julia 1.6 will become the new LTS will be made after it has been battle-tested in the field, around the time of the 1.7 release enters stabilization. The full list of changes can be found in the NEWS file, but here we'll give a more in-depth overview of some of the release highlights.
Parallel precompilation
Ian Butterworth
Executing all of the statements in a module often involves compiling a large amount of code, so Julia creates precompiled caches of the module to reduce this time. In 1.6, this package precompilation is faster and happens before you leave pkg> mode. Until now, precompilation took place solely as a single-processed sequence, precompiling dependencies one-by-one when needed during the linear code loading process when a package is using/import-ed for the first time.
The olden days of <= 1.5, taking as an example DifferentialEquations; a popular package with a particularly high number of dependencies:
(v1.5) pkg> add DifferentialEquations
...
julia> @time using DifferentialEquations
[ Info: Precompiling DifferentialEquations [0c46a032-eb83-5123-abaf-570d42b7fbaa]
474.288251 seconds …In 1.6, pkg> mode gains a heavily parallelized precompile operation that is auto-invoked after package actions, to keep the active environment ready to load.
(v1.6) pkg> add DifferentialEquations
...
Precompiling project...
Progress [========================================>] 112/112
112 dependencies successfully precompiled in 72 seconds
julia> @time using DifferentialEquations
4.995477 seconds …Whereas the previous code loading precompilation process took ~8 minutes to precompile and load DifferentialEquations without indicating progress while doing so, the new mechanism took a little over 1 minute to precompile while showing progress through the dependencies. Then the first time the package is loaded, it loads at full speed. The new parallel precompilation process takes a depth-first approach of working through the dependency tree in the manifest, first precompiling the packages with no dependencies and working upward to the packages listed in the environment’s Project.toml, allowing multiple packages to be precompiled at the same time. The operation is multi-processed, as opposed to multi-threaded, so is not limited by Julia’s thread count. By default, Julia will spawn a maximum CPU-balanced load of package precompile jobs at once based on the number of CPU cores. Errors during precompilation will only throw for packages listed in the Project to allow for dependencies that may be listed in manifests but not loaded, and the auto precompilation process will remember if a package has errored within the given environment and will not retry until it changes. Auto-precompilation can be gracefully interrupted with a ctrl-c and disabled by setting the environment variable JULIA_PKG_PRECOMPILE_AUTO=0.
For packages that are being developed, given that their code will be changed by other mechanisms than Pkg, this new workflow won’t automatically avoid encountering the standard code-load time precompilation. However non-dev-ed dependencies of those packages will be kept ready to load, so top-level precompilation at load time should remain lower for dev-ed packages.
Compile time percentage
Ian Butterworth
A small change that should help understanding of one of Julia’s quirks for newcomers is that the timing macro @time and its verbose friend @timev now report if any of the reported time has been spent on compilation.[1]
julia> x = rand(10,10);
julia> @time x * x;
0.540600 seconds (2.35 M allocations: 126.526 MiB, 4.43% gc time, 99.94% compilation time)
julia> @time x * x;
0.000010 seconds (1 allocation: 896 bytes)Given Julia’s Just In Time (JIT) / Just Ahead Of Time (JAOT) compilation, the first time code is run the compilation overhead is often substantial, with big speed improvements seen in subsequent calls. This change highlights that behavior, serving as both a reminder and a tool for rooting out unwanted compilation effort i.e. over-specialized code.
| [1] | Note that in some cases the system will look inside the @time expression and compile some of the called code before execution of the top-level expression begins. When that happens, some compilation time will not be counted. To include this time you can run @time @eval ... |
Eliminating needless recompilation
Tim Holy
One of Julia’s most powerful features is its extensibility: you can add new methods to previously-defined functions, and use previously-defined methods on new types. Sometimes, these new entities force Julia to recompile code to account for changes in dispatch. This happens in two steps: first, “outdated” code gets invalidated, marking it as unsuitable for use; second, as needed the code is again compiled from scratch taking account of the new methods and types.
Earlier versions of Julia were somewhat conservative, and invalidated old code in some circumstances where there was no actual change in dispatch. Moreover, there were many places where Julia and its standard libraries were written in a way that defeated Julia’s type-inference. Because the compiler sometimes had to invalidate code just because a new method might apply, any uncertainty about types magnifies the risk and frequency of invalidation. In older versions of Julia, the combination of these effects made invalidation widespread: just loading certain packages led to invalidation of up to 10% of Julia’s precompiled code. The delay for recompilation could sometimes make interactive sessions feel sluggish. When invalidation occurred in Julia’s package-loading code, it also delayed loading of the next package, contributing to long waits for using
SomePkg when SomePkg depends on other packages.
In 1.6, the scheme for invalidating old code has been made more accurate and selective. Moreover, Julia and its standard libraries received a thorough makeover to help type inference arrive at a concrete answer more often. The result is a leaner, faster Julia that is far more impervious to method invalidation, and feels considerably more responsive and nimble in interactive sessions. Related blog post: Analyzing sources of compiler latency in Julia: method invalidations.
Compiler latency reduction
Jameson Nash and Jeff Bezanson
In addition to making our library code more compiler-friendly, we continue to try to speed up the compiler itself. This remains one of our main technical challenges. In this release there aren't any major breakthroughs, but we do have some modest improvements due to work on the method table data structure.
Method specificity is a partial order, and prior to 1.6 we stored methods in sorted order. We also attempted to identify ambiguous methods on insertion, hoping to avoid repeating the work for each future query. Unfortunately, sorting a partial order requires quadratic time, and this time began to show up prominently during package loading (when a package's methods need to be inserted into the currently-active method tables).
We improved things by making the process lazier, moving sorting and ambiguity detection into the algorithm for finding matching methods. This algorithm runs very often, so it was not at first intuitive that this change would help. But the key is that the vast majority of queries are for specific enough types that most possible matches can be eliminated easily, leaving many fewer inputs to the most expensive steps.
The main visible improvement here is to package loading, adding a bit of extra speed on top of the gains from addressing invalidations.
There has been substantial effort put into refining our inference quality characteristics, both in stopping analysis quickly when it is perceived to not be of benefit, and extracting more precise information when possible. Both sides of this can have significant benefit for complex code, such as plotting libraries, which branch over large numbers of different configuration options.
Much of this benefit should simply be available without doing anything to your code except updating Julia version! To go even further, there is now also a general framework for profiling compilation times, for investigating what functions contribute most heavily to execution latency. This is described in more detail by others. But with each release, you may just find that an old code pattern, which you used to need to avoid for performance, now works great!
We applied many micro-optimizations to several internal data-structures also. These again won't affect how your code works, but should improve how it performs dynamically. For example, invokelatest is now faster than try, and nearly as fast as dynamic dispatch. Several complex internal data-structures that were trees also became simple hash-tables, improving both their scaling performance and making them more cheaply thread-safe. This affects some key areas such as type allocations (apply_type and tuple), method optimization lookup (MethodInstance), and dispatch (jl_apply_generic).
While we haven't yet reached our target performance levels, we hope this release is a great step forward. There's already other work completed in preparation for getting latency down even more in the future!
Tooling to help optimize packages for latency
Nathan Daly & Tim Holy
Julia 1.6, in conjunction with SnoopCompile v2.2.0 or higher, features new tools for compiler introspection, especially (but not exclusively) for type inference. Developers can use the new tools to profile type inference and determine how particular package implementation choices interact with compilation time. Early adopters have used these tools to eliminate anywhere from a few percent to the large majority of first-use latency.
Related blog post: Tutorial on precompilation
Binary loading speedups
Elliot Saba & Mosè Giordano
Providing reliable, portable binaries to packages is a challenge that all packaging environments must face, and while Julia's strategy has always been to prioritize reliability and reproducibility over all other concerns, in the past it has come at a cost. Our solution to the problems of reliability and reproducibility was to more fully isolate installed binaries and cross-compile them ourselves using the BinaryBuilder.jl framework. Libraries built from BinaryBuilder.jl are most often used through so-called JLL packages which provide a standardized API that Julia packages can use to access the provided binaries. This ease of use and reliability of installation resulted in vastly increased load times as compared to the bad old days when Julia packages would blindly dlopen() libraries and load whatever libraries happened to be sitting on the library search path. To illustrate the issue, in Julia 1.4, loading the GTK+3 stack required 7 seconds when it used to take around 500ms on the same machine. Through many months of hard work and careful investigation, we are pleased to report that the same stack of libraries now takes less than 200ms to load when using Julia v1.6 on the same machine.
The cause of this slowdown was multi-faceted and spread across many different layers of the Julia ecosystem. Part of the issue was general compiler latency, which has been a focus of the compiler team for some time now, as evidenced by the compiler latency reduction section in this blog post. Another major piece though was general overhead incurred by having so many small JLL packages providing bindings; there was significant overhead in the loading of each package. In particular, there was code inference, code generation and data-structure loading that needed to be eliminated if the JLL packages were to be lightweight enough to not affect overall load times. In our experiments, we found that one of the largest sources of package load times was in the deserialization of backedge information, the links from functions in Base back to our packages that would cause our functions to be recompiled if there was an invalidation effecting that Base function. As counter-intuitive as it may seem, simply using a large number of functions from Base can very quickly balloon the precompilation cache files for your package, causing an increase in loading time! While the increase itself is small, (3-10ms at the worst) when you are loading many dozens of JLL packages, this adds up quickly.
Our work to slim JLL packages down resulted in the creation of a new package, JLLWrappers.jl. This package provides macros that auto-generate the bindings necessary for a JLL package, and do so by using the minimum number of functions and data structures possible. By limiting the number of backedges and data structures, as well as centralizing the template pieces of code that each JLL package uses, we are able to not only vastly improve load times, but improve compile times as well! As an added bonus, improvements to JLL package APIs can now be made directly in JLLWrappers.jl without needing to re-deploy hundreds of JLLs. Because these JLL packages only define a thin wrapper around simple, lightweight functions that load libraries and return paths and such, they do not benefit from the heavy optimization that most Julia code undergoes. One final piece of the optimization puzzle was therefore to disable optimizations and use the new per-module optimization levels functionality to reduce the amount of time spent generating a very small amount of code, saving precious seconds.
The interplay between compiler improvements and the benefits that JLLWrappers affords were well-recorded during the development process, and showcase a speedup of load times for the original, non-JLLWrapperized GTK3_jll package from its peak at 6.73 seconds on Julia v1.4 down to 2.34 seconds on Julia v1.6, purely from compiler improvements. If you haven't thanked your local compiler team today, you probably should. Using the slimmed-down JLLWrappers implementation of all relevant JLLWrappers packages results in a further lowering of load time down to a blistering 140ms. End-to-end, this means that this work effected a roughly 50x speedup in load times for large trees of binary artifacts. While there are some minor improvements for lazy loading of shared libraries and such in the pipeline, we are confident that this work will provide a strong foundation for Julia's binary packaging story for the foreseeable future.
Downloads & NetworkingOptions
Stefan Karpinski
In previous releases, when you download something in Julia, either directly, using the Base.download function, or indirectly when using Pkg, the actual downloading was done by some external process—whichever one of curl, wget, fetch or PowerShell happened to be available on your system. The fact that this frankendownload feature worked at all was something of a miracle, that only worked due to much fussy command-line-option finessing of over the years. And while this did mostly work, there were some major drawbacks to this approach.
It’s slow. Starting a new process for each download is expensive; but worse, those processes can’t share TCP connections or reuse already negotiated TLS connections, so every download needs to do the TCP SYN/ACK song and dance and then also do the TLS secret handshake, all of which takes a lot of time.
It’s inconsistent. Since the exact way things got downloaded depended on what happens to be installed on your system, download behavior was terribly inconsistent. Downloads that work on one system might not work on another one. Moreover, any issues someone might have, inevitably end up out of scope for Julia to fix — the typical answer is "fix your system
curl/wget/whatever," which is not a very satisfactory solution for someone using Julia who just wants to be able to download things.It’s inflexible. The core requirements of downloading something are simple: URL in, file out. But maybe you need to pass some custom headers with the request. Or maybe you need to see what headers were returned. Often you want to display progress for large downloads. Some download commands have options for some of these, but we can only support options that are supported by all download methods, which has forced downloads to be pretty inflexible.
In Julia 1.6 all downloading is done with libcurl-7.73.0 via the new Downloads.jl standard library. Downloading is done in-process and TCP+TLS connections are shared and reused. If the server supports HTTP/2, multiple requests to that server can even be multiplexed onto the same HTTPS connections. All of this means that downloads are much faster.
Since all Julia users now use the same method to download things, if it works on one system, it is much more likely to work everywhere. No more broken downloads just because the system curl happens to be really old. And libcurl is highly configurable: we can pass custom headers with requests, see what headers were included with the response, and get download progress — all in the same way everywhere.
As part of reworking downloads, we have switched to using the built-in TLS stack on macOS and Windows, which allows downloads to use the built-in mechanism for verifying the identity of TLS servers via the system’s collection of certificate authority root certificates (“CA roots”, for short). On Linux and FreeBSD, we now also look in the standard locations for a PEM file with CA root certificates. The advantage of using the system CA root certificates is that most systems will automatically keep these CA roots up-to-date and on Windows and macOS the OS will check for revoked certificates when performing certificate verification (Linux doesn't have standard way to do this). Julia itself still ships with a reasonably up-to-date bundle of CA roots, but we no longer use it by default unless system CA roots cannot be found.
Using the system CA roots already means that it’s much more likely that Julia will “just work” from behind firewalls. Many institutional firewalls will man-in-the-middle (MITM) your outgoing HTTPS connections and present a forged HTTPS certificate for the server to your client connection. In order for this not to set off security alarms on your client, they will typically add a private CA root certificate to the user's system so that your browser will accept the firewall’s forged certificate. Since Julia now uses the system’s CA roots, it respects any private CA roots that have been added there.
If this doesn’t work for some reason, Julia 1.6 also introduces the NetworkOptions.jl stdlib: this package acts as a central place for network configuration options that can be controlled by various environment variables and which are used to modify the behavior of networking libraries like libcurl and libgit2 in a consistent way. For example, if you want to turn off HTTPS host verification entirely, you can do export JULIA_SSL_NO_VERIFY_HOSTS="**" in your shell and both the Downloads and LibGit2 packages will not perform host verification when downloading over HTTPS. There are various other options available in NetworkOptions, including:
JULIA_SSL_CA_ROOTS_PATHto provide a custom PEM file of CA rootsSSH_KNOWN_HOSTS_FILESto use non-standard locations for SSH known hostsJULIA_*_VERIFY_HOSTSvariables for fine-grained control over which hosts should or shouldn’t be verified over various transports, including TLS and SSH
These options are now consistently respected across all network-facing code that ships with Julia itself and we will be working with package developers to encourage them to use NetworkOptions for configuration of libraries such as mbedtls and others. This will allow consistent configuration of networking options across the entire Julia ecosystem.
CI Robustness
Jeff Bezanson, Keno Fischer, and Jameson Nash
This release cycle we spent quite a bit of time paying down technical debt in the form of intermittent test failures in our continuous integration (CI) process. Like all responsible software projects these days, we run our full build and test suite for every commit and for every proposed change. If the tests fail, you stop the presses until the problem is fixed — either by reverting a change, committing a new fix, or revising a proposed patch until it passes. Given this simple policy, it’s difficult to see how a project could be ambushed by persistent test failures. And yet that’s exactly what happened to us: over time, we ended up in a state where a high percentage of test runs failed, usually with just a single obscure test case failing.
Several factors contributed to this predicament. First, the base Julia test suite is quite large and covers a wide range of functionality, from parsing and compiling to linear algebra, package management, sockets, threads, handling file system events, and more. With that much surface area, we were likely to end up with a handful of rare bugs, or failures due to overly-fragile tests. We run easily over a hundred builds per day, so even failures with a rate of 0.1% would appear often enough to be disruptive. Timing-sensitive tests are a classic example, e.g. testing that a one-second timeout indeed happens after approximately one second. On hosted VMs in particular, timing can be far more variable than what you would ever see on dedicated hardware. A one-second timeout can, unfortunately, take more than 60 seconds on a heavily loaded VM.
After much debugging, including infrastructure work to run tests under rr by default, we were able to identify and fix many issues. Here is a representative sample:
Remove some overhead to reduce timing variation in Channels test
Fix a calling convention issue causing occasional failures on FreeBSD
Port reuse issue causing occasional Distributed test failure on Darwin
As a result, the proportion of "green check" PRs is noticeably higher. We are not yet at 100%, but CI can now generally be expected to pass.
Improved stacktrace formatting
Kristoffer Carlsson
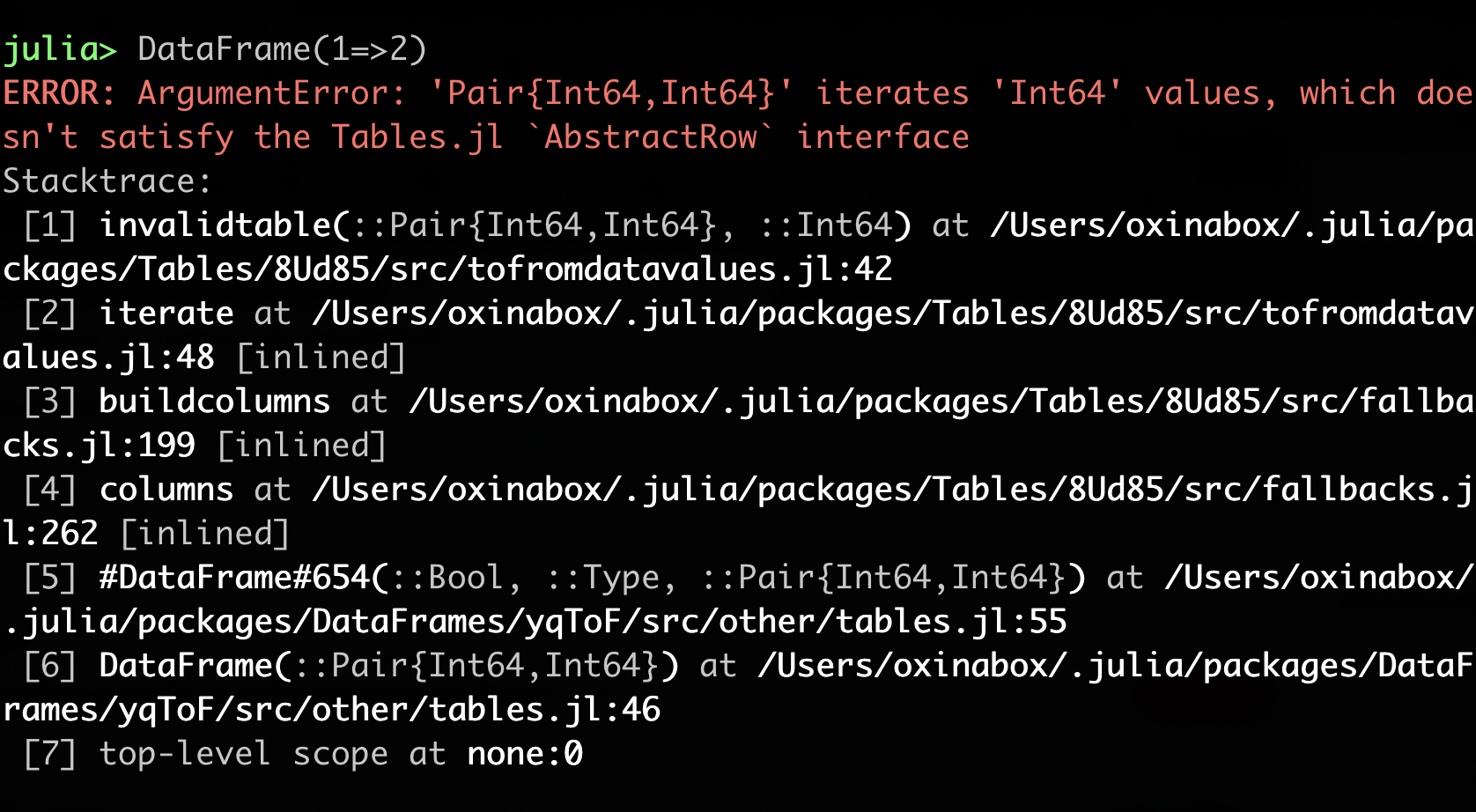
Way back in Julia release 0.6, formatting of stacktraces went through an overhaul and in this release @jkrumbiegel made further improvements on this area (implemented in #36134). Let's look at an example of the old stacktrace printing and compare it to the new one:
Old stacktrace:
New stacktrace:
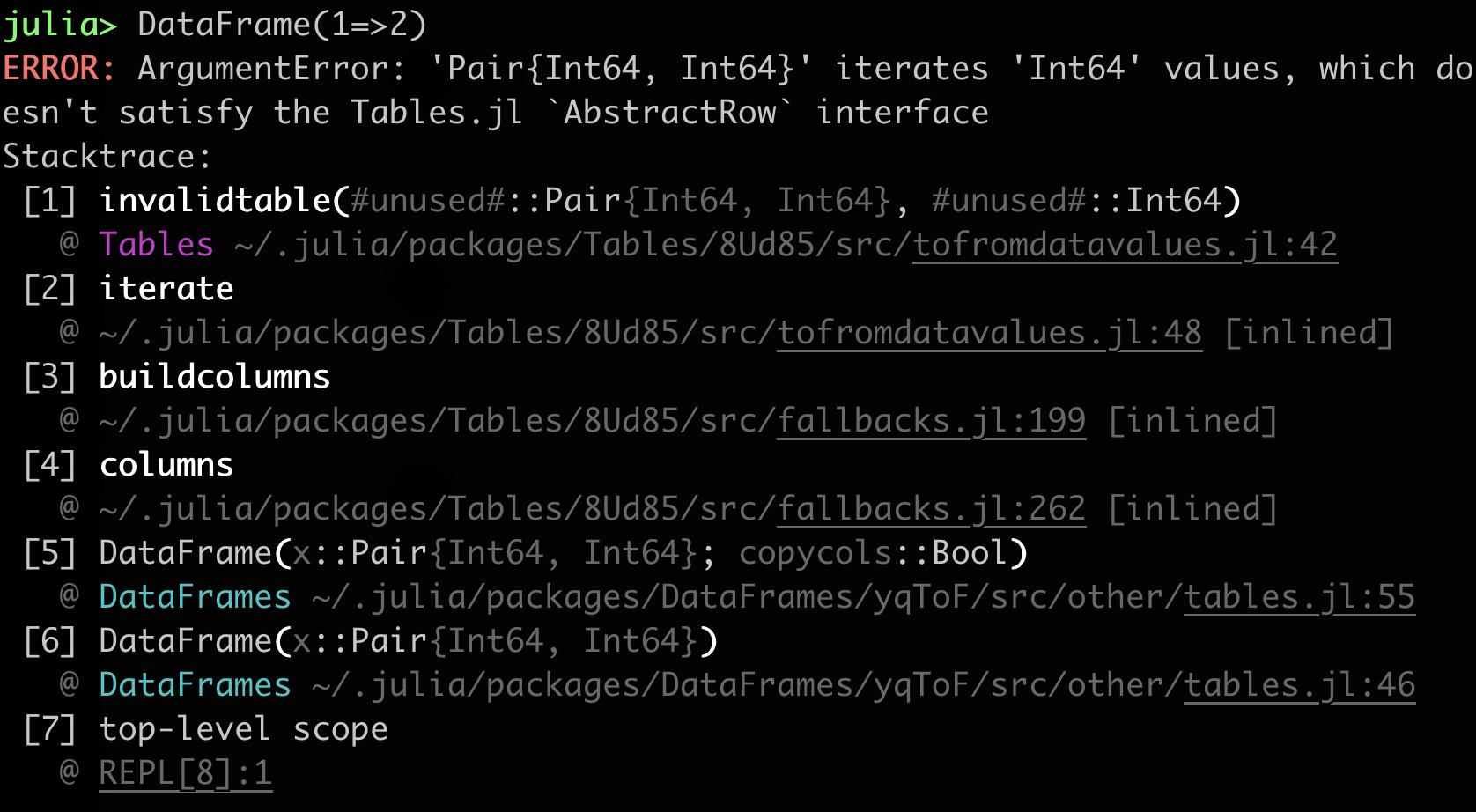
Some improvements are worth pointing out explicitly:
Argument names in methods are now shown.
The function name was made to be more emphasized compared to the surrounding text, since that information tends to be the most important.
The module where the method is defined is now shown and the modules are also color coded.
Paths to the method were de-emphasized since they usually have lower importance.
Paths were made shorter by showing
~instead of the full path to the home directory.
Conclusion
Please enjoy the release, and as always let us know if you encounter any problems or have any suggestions. We hope to be back in about four months to report on even more progress in version 1.7!